מדריך מעשי לפייתון: כך תתחילו לנתח נתונים מאפס – גם בלי ניסיון קודם

אם אתם מרגישים שהגיע הזמן להתחיל להבין נתונים ולא רק להסתכל עליהם מהצד – אתם במקום הנכון. לא צריך ניסיון קודם, לא צריך ידע מוקדם בתכנות. רק סקרנות וקצת סבלנות.
למה דווקא פייתון?
כי זו שפה פשוטה, נעימה לקריאה, ומאחוריה עומדת קהילה עצומה. פייתון עוזרת לאנליסטים, מדענים, מפתחים וסטודנטים – ועם הזמן הפכה לאחת מהשפות הפופולריות ביותר בעולם ניתוח נתונים. כלים כמו Pandas לניהול טבלאות, NumPy לחישובים מתמטיים ו-Matplotlib או Seaborn לגרפים – כולם נגישים, פתוחים וחינמיים. וזה מה שמדהים.
שלב ראשון: הורדת פייתון והתקנת סביבת עבודה
תיכנסו לאתר python.org ותורידו את הגרסה הכי עדכנית. לאחר מכן תפתחו את חלון הפקודה (Windows+R, ואז לרשום cmd) ותכניסו את הפקודה:
pip install jupyter
כדי להפעיל – פשוט תרשמו:
jupyter notebook
זה יפתח לכם דפדפן שבו תעבדו בצורה אינטראקטיבית: תאי קוד, תאי טקסט, גרפים שמופיעים ישר בתוך המסך – הכי נוח ללמידה. זה דומה לגוגל קולאב.
ספריות חובה שתכירו
Pandas: תעבדו עם טבלאות כאילו אתם באקסל – רק עם הרבה יותר שליטה.NumPy: תשתמשו בפונקציות מתמטיות על כמויות גדולות של נתונים – בלי כאבי ראש.Matplotlibו-Seaborn: כאן תתחילו באמת להרגיש שאתם מבינים את הנתונים – דרך גרפים יפים ומדויקים.
להתחיל לקודד
ברגע שסיימנו את ההתקנה של פייתון ו־Jupyter Notebook, אנחנו נכנסים לממשק בדפדפן שיכול להיראות בהתחלה קצת ריק – אבל אל תיבהלו. זה הולך להפוך לכלי העבודה המרכזי שלכם.
כדי להתחיל, פתחו מחברת חדשה מתוך הדפדפן (new → notebook → Python 3) ותראו תא ריק שבו תוכלו להתחיל לכתוב קוד. ברגע שכתבתם שורת קוד, לחיצה על Shift + Enter תריץ את התא. פשוט ככה.
Shift + Enterמריץ את התא ועובר לתא הבאCtrl + Enterמריץ את התא ונשאר באותו תאAlt + Enterמריץ את התא ויוצר תא חדש מתחתיו
דוגמה לקוד פשוט שמדפיס הודעה
print('hello world')ככה מתחילים. חשוב להבין ש־Jupyter Notebook מאפשר לא רק להריץ קוד אלא גם לשלב איתו הסברים. אפשר להוסיף תאי טקסט (Markdown), לשלב כותרות, הסברים ותיעוד. זו הדרך הנכונה לבנות תהליך שלם של ניתוח נתונים – כמו סיפור שצומח שלב אחר שלב.
שמירה ופתיחה של מחברות קיימות
בכל פעם שאתם שומרים את המחברת, נוצר קובץ עם סיומת ipynb בתיקייה שבה התחלתם את העבודה. זה קובץ חי – כשאתם פותחים אותו שוב, תראו גם את הקוד וגם את הפלט שנוצר. לא צריך להריץ הכול מחדש (אם כי לפעמים כדאי).
כלים בסיסיים לפיתוח סקריפטים של ניתוח נתונים
כדי להתחיל לעבוד עם נתונים, נרצה לטעון ספריות שימושיות. בואו נייבא את השלוש הבסיסיות:
import pandas as pd # לעבודה עם טבלאות ונתונים import numpy as np # לפעולות מתמטיות וסטטיסטיות import matplotlib.pyplot as plt # להדמיית נתונים
אם עדיין לא התקנתם את הספריות האלו, פשוט הריצו בשורת הפקודה (CMD):
pip install pandas numpy matplotlib
יצירת טבלה בסיסית עם pandas
כשאנחנו מקבלים קובץ CSV או אקסל ממקור כלשהו – לקוח, מרצה, או פשוט פרויקט אישי – הצעד הראשון הוא להציץ בו. להרגיש את הנתונים. וזה בדיוק מה ש־Pandas מאפשרת לנו לעשות בצורה הכי נוחה שיש.
data = {
'Name': ['Dana', 'Ori', 'Michal'],
'Age': [28, 34, 22],
'Salary': [9500, 11200, 8700]
}
df = pd.DataFrame(data)
print(df)פלט:
Name Age Salary 0 Dana 28 9500 1 Ori 34 11200 2 Michal 22 8700
אפשר לחשוב על זה כאילו זה גיליון אקסל – רק שאתם שולטים בו עם קוד. היתרון? אפשר לסנן, לחשב, לצבור ולשמור בדיוק איך שאתם רוצים.
פעולות בסיסיות: חיתוך, מיון וחישובים
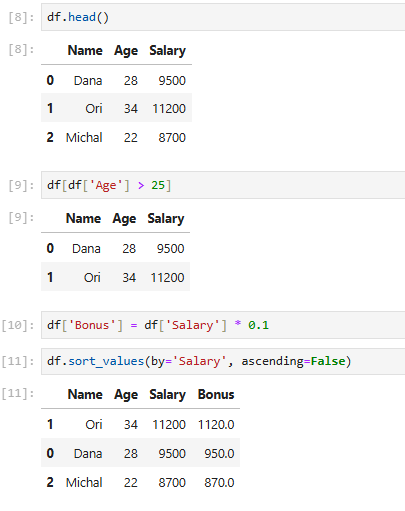
צפייה בראש הטבלה
שימושי לבדיקה ראשונית של מבנה הנתונים: אילו עמודות קיימות, מה הטיפוסים, האם יש ערכים חריגים או שגויים.
df.head()
סינון לפי תנאים
ברגע שהנתונים טעונים – נרצה להתחיל לעבוד רק עם מה שמעניין אותנו. לדוגמה:
df[df['Age'] > 25]
הוספת עמודה חדשה
מנתחי נתונים כמעט תמיד מוסיפים "עמודות מחושבות" – כלומר ערכים חדשים שמבוססים על עמודות קיימות. נניח שאנחנו רוצים לחשב בונוס של 10% מהשכר:
df['Bonus'] = df['Salary'] * 0.1
מיון לפי שכר
אפשר גם לחשב סכומים שנתיים, בונוסים מדורגים, ואפילו לוגיקות מורכבות עם תנאים:
df.sort_values(by='Salary', ascending=False)
וכך זה אמור להראות ב-Jupyter:
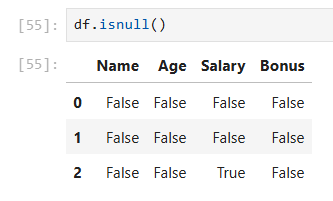
ערכים חסרים: בנתונים אמיתיים כמעט תמיד יש ערכים חסרים – לפעמים שורה בלי גיל, עמודה עם רווח ריק, או שגיאת הקלדה.
נכניס בכוונה ערך חסר:
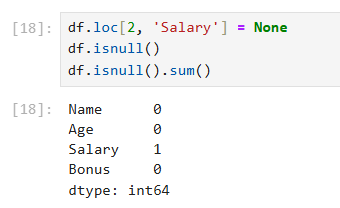
df.loc[2, 'Salary'] = None #הופך את הפריט השני לערך חסר df.isnull() #לבדוק ערכים חסרים
df.isnull().sum() #לבדוק כמה ערכים חסרים יש בסך הכל
אפשר למחוק את השורה:
df.dropna(inplace=True)
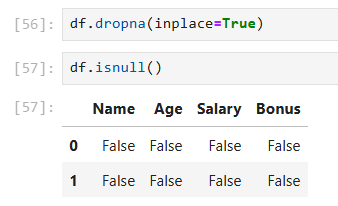
סטטיסטיקה בסיסית על העמודות
print("ממוצע שכר:", df['Salary'].mean())
print("סטיית תקן:", df['Salary'].std())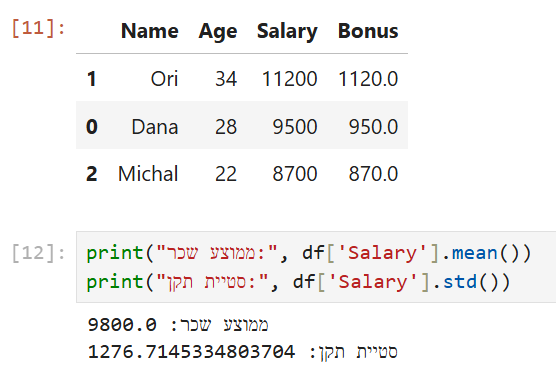
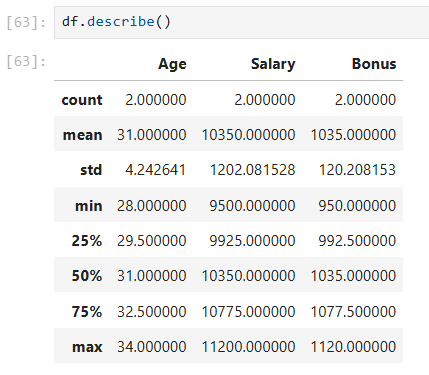
אפשר גם לראות הכול יחד:
df.describe()
קיבוץ וניתוח לפי קטגוריות
עכשיו נוסיף עמודה של "מחלקה" לעובדים:
df['Department'] = ['HR', 'IT']
ואז נחשב שכר ממוצע לפי מחלקה:
grouped = df.groupby('Department')['Salary'].mean()
print(grouped)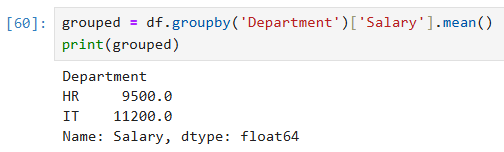
הדמיה פשוטה של הנתונים
גרף עמודות של שכר לפי שם
plt.bar(df['Name'], df['Salary'])
plt.title('Salary by workers')
plt.xlabel('Name')
plt.ylabel('Salary')
plt.show()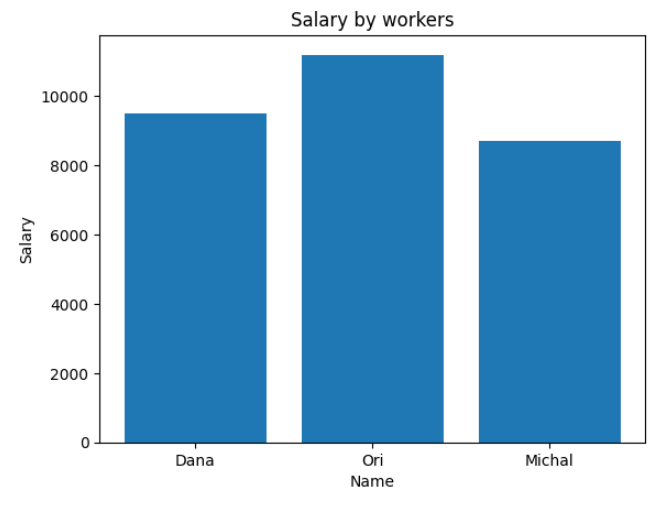
גרף עוגה
plt.pie(df['Salary'], labels=df['Name'], autopct='%1.1f%%')
plt.title('Salary Distribution')
plt.axis('equal')
plt.show()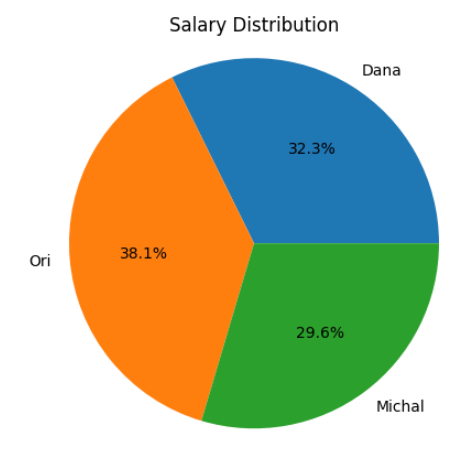
גרף עמודות
import matplotlib.pyplot as plt
grouped.plot(kind='bar', color='skyblue')
plt.title('Average Salary by Department')
plt.ylabel('Salary')
plt.xlabel('Department')
plt.xticks(rotation=0)
plt.grid(True)
plt.show()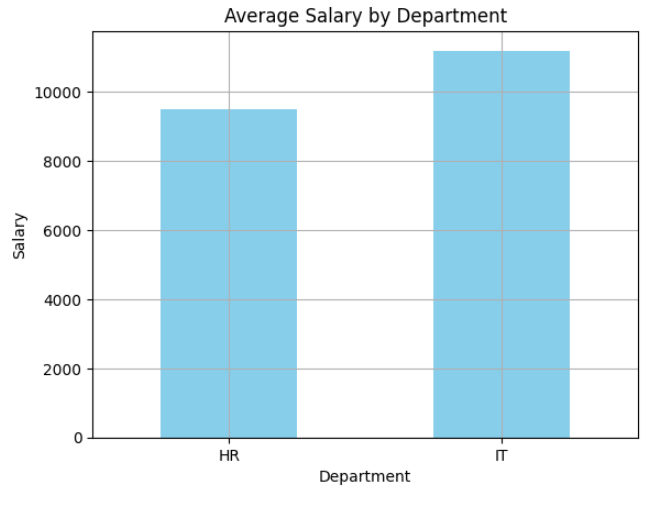
תארו לכם שאתם עובדים במחלקת שכר של ארגון – זה בדיוק סוג הגרף שתצטרכו להכין למצגת רבעונית.
התפלגות שכר (היסטוגרמה)
plt.figure(figsize=(10, 6))
plt.hist(df['Salary'], bins=50, edgecolor='black', color='skyblue')
plt.title('Salary Distribution of 5,000 Workers')
plt.xlabel('Salary (₪)')
plt.ylabel('Number of Workers')
plt.grid(axis='y')
plt.show()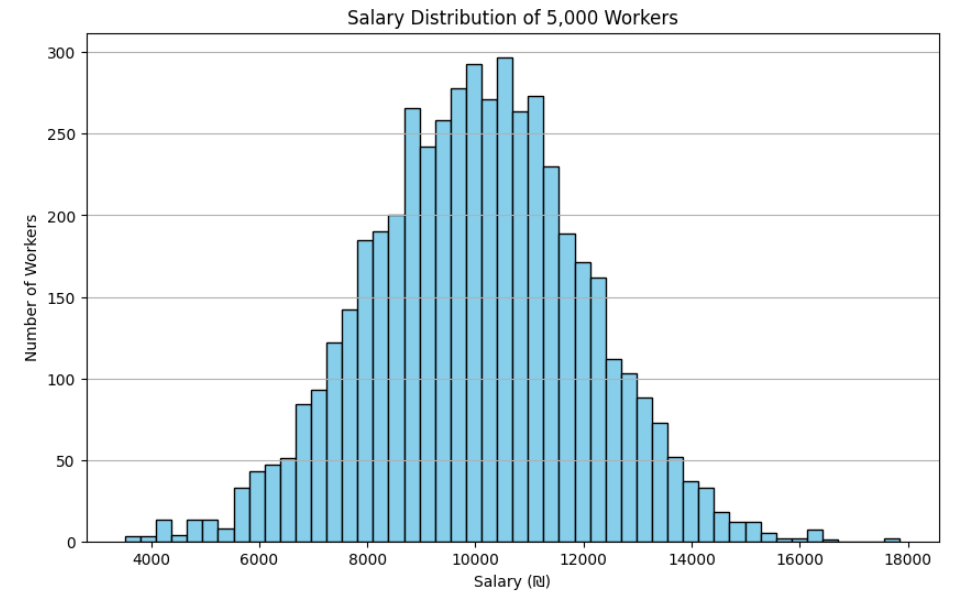
גרף קופסא (Boxplot)
plt.boxplot(df['Salary'])
plt.title('Salary Boxplot')
plt.ylabel('Salary')
plt.grid(True)
plt.show()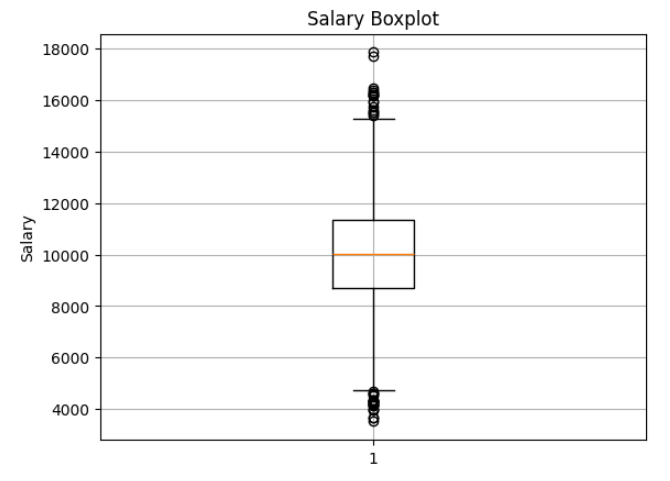
היסטוגרמה מראה לנו איך השכר מתפלג – קופסה מסמנת קיצוניים, ממוצע וחציון.
סימולציה בלוטו – או: איך נראים נתונים רנדומליים?
הנה דוגמה שמלמדת גם סטטיסטיקה וגם תכנות ב־NumPy.
נניח שהסיכוי לזכות בלוטו הוא 1 ל־1,000,000:
import numpy as np
draws = np.random.choice(['Win', 'Lose'], size=1_000_000, p=[0.000001, 0.999999]) win_prob = np.sum(draws == 'Win') / len(draws) print("Estimated chance of winning the lottery:", win_prob)

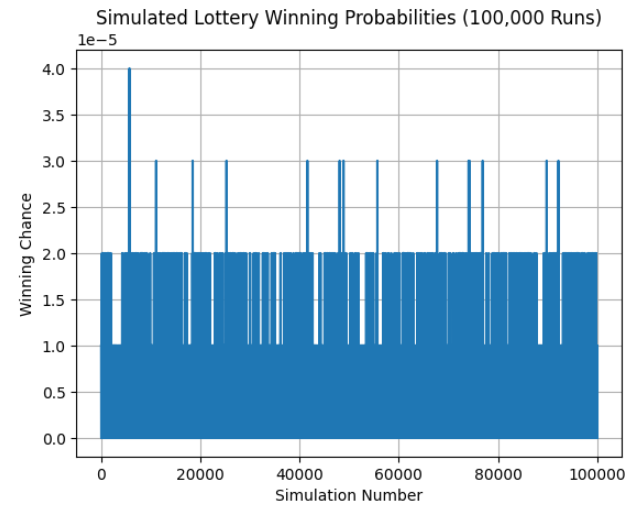
נמחיש את זה עם סימולציות חוזרות
הרבה פעמים כשאנחנו לומדים הסתברות, זה נשאר תיאורטי: "הסיכוי לזכות בלוטו הוא אחד למיליון" – אבל מה זה אומר בפועל? מה קורה אם נריץ את זה אלפי פעמים? כאן בדיוק נכנסת הסימולציה.
הקוד הבא מדגים איך פייתון יכולה לעזור לנו לדמות אלפי "הגרלות לוטו", ואז לבדוק כמה פעמים באמת הייתה זכייה. המטרה היא להבין איך נראית הסתברות של אירוע נדיר כשמריצים אותו שוב ושוב.
simulations = []
for i in range(1000): draw = np.random.choice(['Win', 'Lose'], size=1000, p=[0.000001, 0.999999]) chance = np.sum(draw == 'Win') / len(draw) simulations.append(chance) plt.plot(simulations) plt.title('Simulated Lottery Winning Probabilities (1000 Runs)') plt.xlabel('Simulation Number') plt.ylabel('Winning Chance') plt.grid(True) plt.show()
אנחנו יוצרים רשימה ריקה שבה נאחסן את התוצאה של כל סימולציה — כלומר, מה היה הסיכוי בפועל לזכייה בכל הרצה.
אנחנו מריצים את אותו ניסוי 100,000 פעמים. כל הרצה מייצגת קבוצת אנשים שמילאו לוטו.
בכל פעם, אנחנו מדמים 100,000 כרטיסי לוטו. כל אחד מהם הוא או "Win" או "Lose" — עם הסתברות של:
- 0.000001 לזכייה (שזה אחד למיליון)
- 0.999999 להפסד
הבחירה היא אקראית, בדיוק כמו במציאות.
אנחנו סופרים כמה כרטיסים מתוך ה־100,000 שזכו (draw == 'Win')
ומחלקים באורך הרשימה (כלומר 100,000) כדי לקבל את השיעור בפועל של זכיות בסימולציה הזאת.
מוסיפים את התוצאה (למשל 0.0 או 0.00001) לרשימת התוצאות הכוללת שלנו.
ואז אנחנו יוצרים גרף שמראה לנו איך הסיכוי האמיתי משתנה בין כל הרצה. לפעמים הוא 0.0 (כלומר אף אחד לא זכה), לפעמים יש פתאום קפיצה – מישהו אחד זכה, אולי אפילו שניים.
זה בדיוק מה שמנתחי נתונים עושים כשהם בונים מודלים הסתברותיים או בודקים תרחישים עתידיים: הם מריצים המון סימולציות (מה שנקרא Monte Carlo simulations), כדי להבין איך המציאות יכולה להיראות בממוצע, או איפה יש חריגים.
הדמיות מתקדמות עם Seaborn
מעבר לניתוחים בסיסיים, פייתון מציעה גם כלים מתקדמים להדמיה. להלן מספר דוגמאות שימושיות עם ספריית Seaborn:
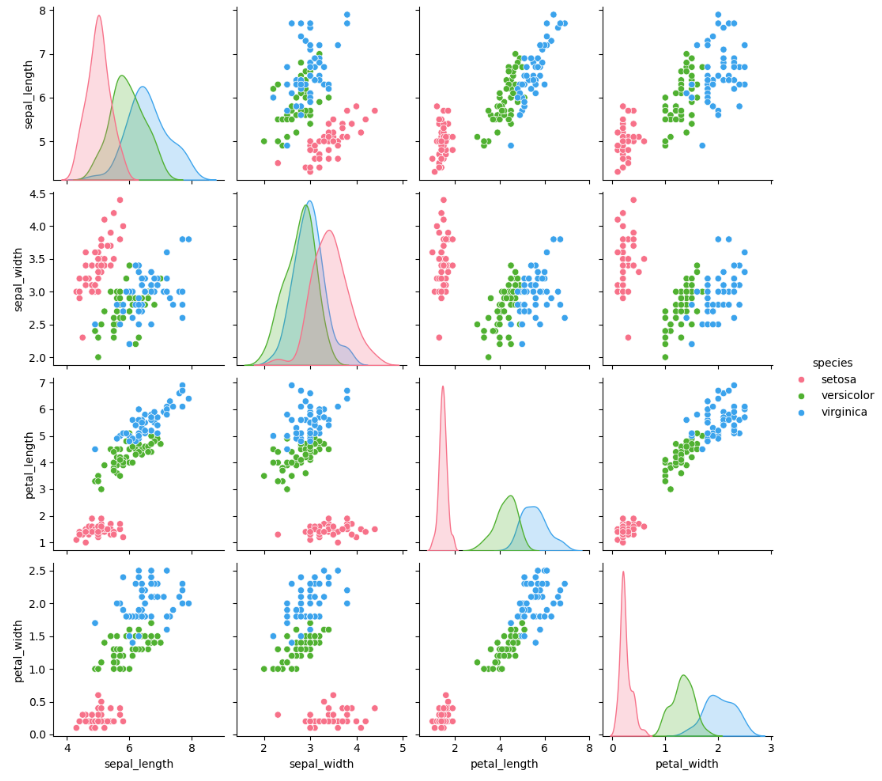
Pair Plot (זוגות גרפיים)
דוגמה זו מציגה את מערך הנתונים "iris" ויוצרת גרף זוגי המציג את הקשרים בין המשתנים השונים.
import seaborn as sns import matplotlib.pyplot as plt from sklearn.datasets import load_iris
# טעינת מערך הנתונים iris iris = load_iris() iris_data = sns.load_dataset('iris') # יצירת Pair Plot sns.pairplot(iris_data, hue="species", palette="husl") plt.show()
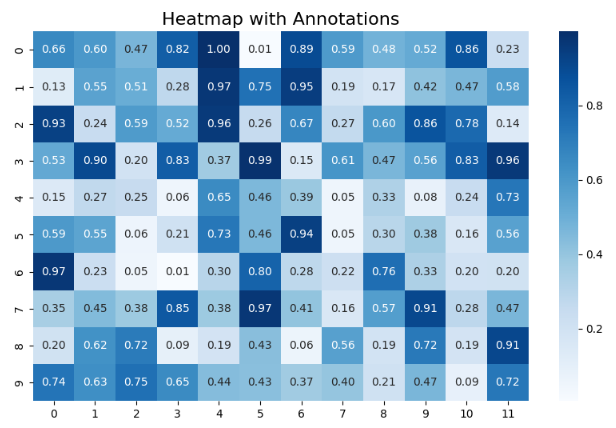
Heatmap (מפת חום עם אנוטציות)
בואו ניצור Heatmap שמציג נתונים רנדומליים ומאופיין באנוטציות שמציגות את הערכים.
import seaborn as sns import matplotlib.pyplot as plt from sklearn.datasets import load_iris
# יצירת נתונים לדוגמה data = np.random.rand(10, 12) plt.figure(figsize=(10, 6)) sns.heatmap(data, annot=True, fmt=".2f", cmap="Blues") plt.title('Heatmap with Annotations', fontsize=16) plt.show()
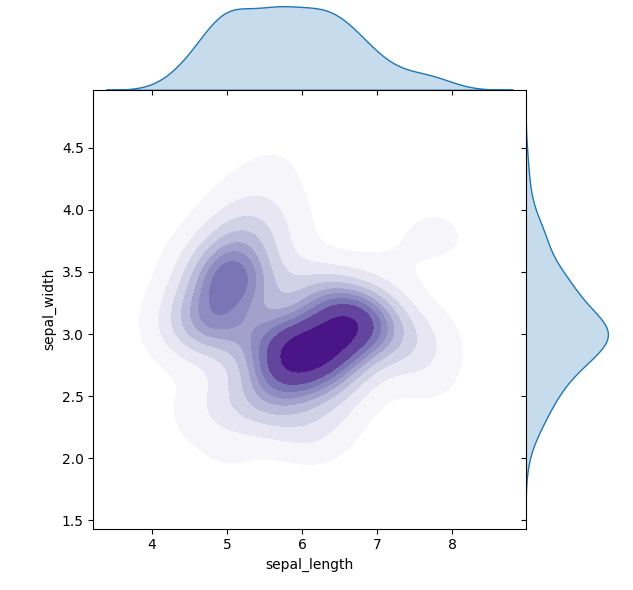
Joint Plot (גרף התפלגות משותף)
דוגמה זו מציגה את הקשר בין שני משתנים במערך הנתונים iris, תוך שימוש בהדמיית התפלגות (KDE).
import seaborn as sns import matplotlib.pyplot as plt
# טעינת מערך הנתונים iris data = sns.load_dataset('iris') # יצירת Joint Plot sns.jointplot(x='sepal_length', y='sepal_width', data=data, kind="kde", space=0, fill=True, cmap="Purples") plt.show()
Swarm Plot (גרף התפזרות)
גרף זה מציג את התפלגות אורך עלי הפרח לפי המין, תוך שימת דגש על קבוצות שונות במערך הנתונים iris.
import seaborn as sns
import matplotlib.pyplot as plt
# טעינת מערך הנתונים iris
data = sns.load_dataset('iris')
# יצירת Swarm Plotsns.swarmplot(x='species', y='petal_length', data=iris, palette='Set2')
plt.title('Swarm Plot Example', fontsize=16)
plt.show()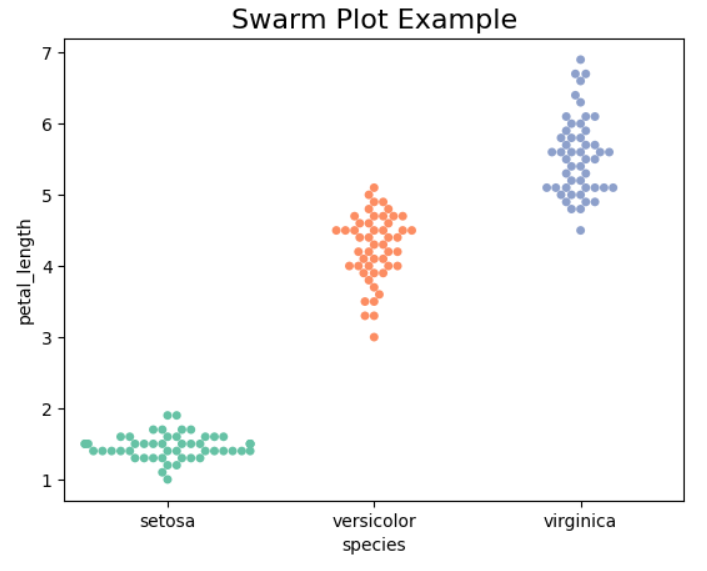
R או פייתון: הבדלים ומקרי שימוש
בשוק של היום ישנם כלים רבי עוצמה לניתוח נתונים, ואחד מהשאלות החשובות אצל מנתחי נתונים הוא – באיזו שפה כדאי לעבוד?
נבחן את R מול פייתון:
- R נוצרה במיוחד עבור מחשוב סטטיסטי והדמיות נתונים. היא כל כך פופולרית באקדמיה ובקרב סטטיסטיקאים, בזכות הפשטות שבה ביצוע ניתוחים מורכבים במינימום קוד.
- פייתון היא שפת תכנות למטרות כלליות, רב-תכליתית וקלה ללמידה. עם מערכת אקולוגית עשירה של ספריות כגון Pandas, NumPy, Matplotlib, Seaborn ועוד, פייתון מאפשרת עבודה לא רק בנתונים אלא גם בלמידת מכונה, ניתוח ביג דאטה ופיתוח יישומים.
למרות ש־R מצטיינת בניתוחים סטטיסטיים וביצירת הדמיות מתקדמות, פייתון נבחרת לעיתים קרובות עבור פרויקטים שדורשים מדרגיות, אינטגרציה ופיתוח כלים יישומיים. בשורה התחתונה – שתי השפות מסוגלות לבצע משימות דומות, והבחירה ביניהן תלויה בהעדפה אישית ובדרישות הפרויקט.
סיכום
השימוש בפייתון לניתוח נתונים מציע גמישות אדירה:
- מצד אחד, ישנם כלים פשוטים ונוחים לעבודה עם מערכי נתונים (כמו Pandas ו־NumPy).
- מצד שני, הספריות להדמיה (כמו Matplotlib ו־Seaborn) מאפשרות לכם להמחיש את הנתונים בצורה מרהיבה ואינטואיטיבית.
- לעומת זאת, R מציעה יתרונות סטטיסטיים והדמיות מתקדמות בפשטות מרשימה, אך כשמדובר במדרגיות, אינטגרציה או פיתוח יישומים – פייתון מובילה את השוק.
עם הזמן, ככל שתצברו ניסיון, תוכלו להרחיב את הידע שלכם לכלול נתונים גדולים, למידת מכונה וניתוחים מתקדמים יותר – מה שיפתח בפניכם דלתות להזדמנויות קריירה רבות.
אז למה לחכות? התחלו את מסע הפייתון שלכם כבר היום – קחו קורס חינמי, הורידו את פייתון, והתחילו לחקור את העולם המרתק של ניתוח נתונים. העולם המודרני, שמונע על ידי נתונים, מחכה לכם, וכל כלי שתלמדו כעת יעזור לכם לקבל החלטות משמעותיות.