תכנות בשפת R: המדריך למתחילים

שפת תכנות R
בבלוג הזה נראה לכם למה שווה להשתמש בדבר הנפלא שנקרא R. נכנס ממש בקצרה לשימושים ולשלבים ההתחלתיים של תכנות.
למה להשתמש ב-R?
הרבה אנשים לא מבינים את ההבדל בין תכנות סטטיסטי לתוכנה סטטיסטית. אתם ודאי מכירים תוכנות כמו אקסל SPSS, JASP, JAMOVI, MATHLAB, JMP ועוד, תלוי מאיזה עולם תוכן אתם באים.
סביר להניח שמי שקורא את הפוסט הזה מכיר את התוכנה SPSS. למי שלא, זו תוכנה סטטיסטית שאפשר לסדר בה נתונים ולהריץ בה ניתוחים סטטיסטיים.
עכשיו, אתם ודאי שואלים, מה ההבדל? למה שאני אלמד תכנות מאפס כשאני יכול פשוט להשתמש בתוכנה עם פקודות שהם כבר מוכנות? ההבדל הוא, שהאופציה השנייה מונעת מכם ליצור, ללמוד ולנסות דברים חדשים. תחשבו על זה – הפקודות המוכנות בתוכנות הסטטיסטיות הם סטטיות, אתם לא יכולים לשנות אותן, וגם אם כן אז באופן מאוד מוגבל.
אם אתם לומדים תכנות, לא רק שזה מתורגם להרבה שפות אחרות, כי יש הרבה משותף, אלא גם אתם לומדים שפה חדשה, שפה של ניתוח סטטיסטי. בזמן שהאדם הממוצע שלא יודע תכנות הולך ומשלם 1,000 שקל בשנה רק בשביל שתהיה לו גישה לתוכנה כמו SPSS, JMP או MATHLAB, תכנות ב-R הוא חינמי לחלוטין!
בטווח של שנה, אתם יכולים ללמוד בתכנות הרבה יותר ממה שהתוכנות הקודמות היו מציעות לכן באותו הזמן. שפת תכנות R היא יחסית ותיקה והופיעה בשנות ה-90. הקהילה של שפת תכנות זו היא עדיין פעילה ואפילו שופעת היום. יש הרבה אנשים שמוסיפים הרבה תוכן לתוכנה הזו שאתם יכולים להשתמש בו, בחינם.
אחד היתרונות הגדולים של שפה זו, ובכלל בתכנות סטטיסטי, היא שאתם יוצרים את הכלים, מודלים והמבחנים הסטטיסטיים של עצמכם. נניח שאתם עושים מחקר חדשני על המוח, אין דרך סטטיסטית נגישה לבדוק את מה שאתם רוצים דרך תוכנה כמו SPSS או JMP. באופן ידני אתם לא תעשו את זה, אבל עם תכנות זה יכול להפוך עבודה של שנה לעבודה של 5 דקות.
למי זה מתאים?
שפת התכנות R שימושית במיוחד עבור אנשים שלומדים בתארים ועוסקים בתחומים שכוללים ניתוח נתונים, מחשוב סטטיסטי והדמיה מחשובית. הנה כמה תתומים שבהם R שימושי עד מאוד:
- סטטיסטיקה ומתמטיקה
- מדעי נתונים וביג דאטא
- בינה מלאכותית ולמידת מכונה
- כלכלה ואקונומטריה
- ביולוגיה ורפואה
- פסיכולוגיה
- מדעי החברה
- מדעי הסביבה
- עסקים ופיננסים
תכנות ב-R לסטודנטים
אני לא יכול להדגיש מספיק עד כמה התוכנה הזו עזרה לי באופן אישי בהבנה עמוקה של סטטיסטיקה. בדרך כלל כשמלמדים סטודנט סטטיסטיקה, שואלים אותו את השאלות הקשות – השאלות התאורטיות שלפעמים מאוד קשה לבדוק. שאלות על מבחנים, וכל המדדים המרכיבים אותם – מה יקרה אם תשנו מדד אחד, או כמה, איך זה ישפיע על המבחן, או על שאר המדדים בו? זה מסוג השאלות שקשה לענות עליהן מכיוון שאין לסטודנט זמן לאסוף נתונים או לבנות מודלים רק בשביל לראות מה יקרה. אומנם זה יחסית פשוט לשנות סטיית תקן או ממוצע לערך אחר, אבל זה לא כל כך פשוט כשאתם מתחילים לעבוד עם סדרי נתונים גדולים יותר.
זה כמו שישאלו אתכם מה יקרה אם תפילו בניין בדרכים שונות? אם באמת תעשו את זה, זה יקח הרבה זמן לבנות אותו מחדש. זה יקח לכם שנים רק בשביל להבין את כל האפשרויות שיכולות להתרחש בכל מקרה נתון. תארו לעצמכם שאתם יכולים לעשות סימולציה של בניין, להפיל אותו באלף או יותר דרכים שונות, וללמוד מזה משהו, בכמה דקות. כאן נכנס תכנות, כי יש לכם בעצם שליטה מלאה על הנתונים ומה שקורה איתם. העבודה היא מאוד מהירה גם, כי המחשב עושה הכל עבורכם.
לי באופן אישי תכנות סטטיסטי עזר בכמה דברים: הבנה מתמטית (שהרבה אנשים מתקשים איתה), הבנה של תכנות (תכנות יעזור לכולם בעידן הזה, במיוחד בקרוב), וסטטיסטיקה. כשעליתי על הדבר הזה, הרגשתי כאילו זמן העיסוק שלי בסטטיסטיקה ובנתונים חילק את עצמו ב-5. וחוץ מזה, למדתי עוד כל כך הרבה דברים שאפשר לעשות עם זה על הדרך.
בפרק הבא אני אתן קצת מבוא לתכנות, וכמה דברים בסיסיים שאפשר לעשות עם פקודות פשוטות ונתונים. זה ממש לא מדריך מלא לתכנות, זו רק טעימה ממה שאפשרי, ואינני חושב שאני אוכל באמת להעביר עד כמה R שימושי בבלוג פוסט אחד בלבד.
גם למי שלומד למבחן המתא"ם - הדבר הזה יכול מאוד מאוד לעזור לכם. מה שחשוב במתא"ם הוא חשיבה יצירתית ותאורטית. אתם יכולים ללמוד כל כך הרבה מהתכנות בגלל שאתם יכולים לשחק עם ולשנות בקלות נתונים כדי להבין טוב יותר את המבחן הסטטיסטי. גם מאוד קל ליצור גרפים ולראות איזה שינויים מתרחשים על סמך השינויים בנתונים. אני מאוד ממליץ למי שניגש למבחן המתא"ם לקרוא את הפוסט הזה ולהתנסות קצת עם התוכנה.
חלק 1: הבסיס
לפני שבכלל נדבר על תכנות, נתחיל מכמה מושגים בסיסיים:
- Vector \ וקטור – הוקטור מכיל את הנתונים. תחשבו על זה כמו קופסא. וקטור יכול להיות מסוגים שונים (כמותי, איכותני, הגיון ועוד).
- Array \ מערך – זהו מבנה של נתונים. מערך יכול להכיל בתוכו מבנים וסדרים שונים של נתונים. תחשבו על זה כמו סדר של קופסאות (וקטורים). מערך יכול להכיל כמה מימדים (במקום שיהיו בו רק קופסאות לאורך ולרוחב, יכולים להיות בו גם קופסאות לגובה, למשל).
- List \ רשימה – רשימה היא אובייקט שיכול להכיל הרבה סוגים של נתונים. תחשבו על זה כמו סל, שיכול להכיל קופסאות מסוגים שונים (וקטורים עם נתונים כמותיים, איכותניים ועוד).
- Data Frame \ מסגרת נתונים – מסגרת הנתונים היא כמו מבנה של טבלה. זאת כמו הטבלה הרגילה שאתם רואים באקסל. לטבלה יש שורות (מצד לצד) ועמודות (מלמעלה למטה). כל עמודה יכולה להכיל סוגים שונים של נתונים (כמותי, איכותני ועוד).
- Matrix \ מטריצה – מטריצה היא סוג מסוים של מערך, אבל המטריצה מוגבלת בעיקר למבנה דו מימדי (יש X ויש Y). ההבדל בין מטריצה לבין מסגרת נתונים הוא שבמטריצה כל הנתונים חייבים להיות מאותו הסוג.
- Argument \ ארגומנט – פיסות מידע שנותנים לפונקציות כדי שהן יוכלו לעשות משהו עם המידע הזה. לדוגמא, אם יש פונקציה של ממוצע, המספרים שניתן לפונקציה יהיו הארגומנט. לפונקציה יכולים להיות מספר ארגומנטים. ישנן פונקציות שלא צריכות בכלל ארגומנט, ויש כאלה שצריכות כמה אגרומנטים.
- Function \ פונקציה – הפונקציה היא כמו מכונה קטנה. נותנים לפונקציה קלט (מידע שנכנס) והפונקציה עושה פעולה כלשהי על המידע הזה, ומחזירה אותו בתור פלט (המידע שיוצא). לדוגמא אם נקח פונקציה של ממוצע, הקלט יהיה הנתונים שלנו, והפלט יהיה הממוצע. זה כמו תא עצב, בעצם.
- Parameters \ פרמטרים – דומה לאגרומנטים, אבל הפרמטרים כבר בנויים לתוך הנוסחא. הם בעצם "תופסים מקום" עד שיחליפו אותם ארגומנטים שהפונקציה תקבל. לדוגמא, אם ניצור פונקציה שתעשה חישוב של טעות תקן, לפונקציה יהיו 2 פרמטרים: האחד יהיה ממוצע, והשני יהיה סטיית תקן. הפרמטרים האלה רק תופסים מקום, עד שנכניס את המידע עצמו לפונקציה. הפונקציה יכולה להראות כך, כאשר X יהווה את הפרמטר ממוצע, ו-Y יהווה את הפרמטר סטיית תקן. בעצם, הפונקציה מבצעת פעולה על הפרמטרים שבתוך הסוגריים. לדוגמה:
Std.error(x,y)
- Object \ אובייקט – אובייקט בתכנות הוא אוסף של מידע, שיטות או נתונים שעושים פעולה כלשהי. תחשבו על זה כמו מחברת. כל מחברת יכולה להכיל סוגים שונים (תכונות) של מידע, כמו למשל מספר הדפים, גודל המחברת, סוג כריכה, סוגים שונים של שימוש במחברת וכו'. בתכנות יש אובייקטים שונים, והם יכולים להיות פשוטים (למשל מספר יחיד או אובייקט) ומורכבים (מסגרת נתונים גדולה). למשל, ב-R אובייקט של מסגרת נתונים יכול להכיל תכונות שונות (סוגים שונים של נתונים) ושיטות (פעולות שאפשר לבצע על אותו אובייקט, כמו למשל סידור מחדש או יצירה של גרף). אובייקט למעשה יכול להתייחס לכל דבר: מבנה נתונים, ערך, פונקציה ועוד. המשתנה הפשוט נחשב לאובייקט, ויש אובייקטים שמכילים בתוכם מבנים מורכבים יותר של נתונים ומידע.
התקנה ושימוש ב-R
אפשר להוריד את התוכנה הבסיסית של R כאן:
https://cran.case.edu/bin/windows/base/R-4.3.3-win.exe
זאת תהיה הדרך שלנו ללמד את המחשב שלנו איך להשתמש בשפת ה-R. אנחנו נוריד עוד תוכנה שהיא סביבת פיתוח משולבת בשביל R (IDE). זאת תוכנה שמסייעת לנו לפתח תוכנה באמצעות שפה מסוימת יותר בקלות. נשתמש בדוגמא שלנו ב-RStudio, שאפשר להוריד כאן:
(שימו לב שאתם יכולים להוריד רק את Rstudio וגם את שפת הבסיס של R באותו העמוד, לבחירתכם).
הממשק של RStudio
הממשק הוא יחסית פשוט. בכניסה הראשונה שלכם תראו מערך בערך כזה:
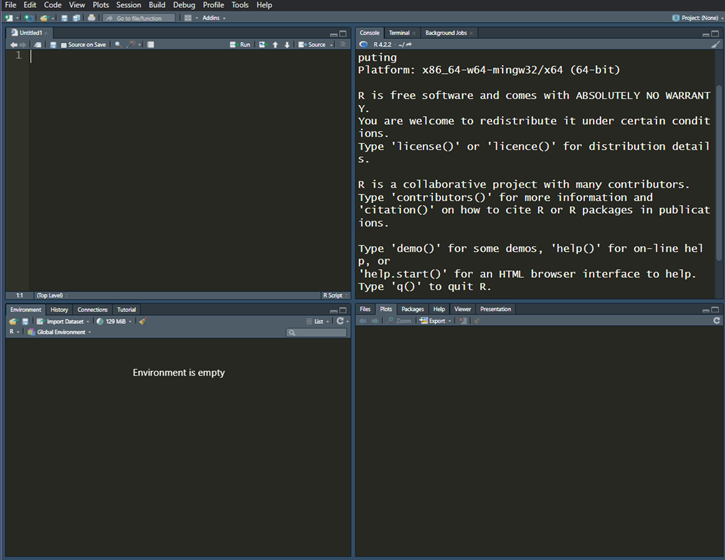
אם הממשק לא נראה כך, לא נורא. אתם יכולים להחליף את סדר הפאנלים דרך View. יש לנו כאן כמה פאנלים:
- למעלה מצד שמאל, יש לנו את פאנל הקוד. כאן אנחנו רושמים את הקוד שלנו ומריצים אותו.
- למעלה מצד ימין, יש את הקונסולה. כאן נראה בעצם את הפלט שלנו. אם נריץ קוד בפאנל מצד שמאל הוא יופיע בקונסולה.
- למטה מצד שמאל, יש את ה-Environment. זה כמו הזכרון של Rstudio. כל משתנה חדש, מסגרת נתונים או אובייקט חדש שניצור יופיע כאן.
- למטה מצד ימין זה פאנל שאפשר להעזר בו בשביל להבין מה פקודות עושות בלשונית ה"help". כאן גם אפשר לראות פלטים של גרפים ועוד דברים שלא נדבר עליהם בהיקף הבלוג הזה.
כשאנחנו כותבים קוד ב-Rstudio אנחנו יכולים להריץ אותו דרך קיצור דרך (Ctrl + Enter) או דרך כפתור ההרצה למעלה "Run". הפקודה תריץ כל שורה בנפרד, אלא אם כן נסמן כמה שורות ונריץ אותן ביחד. לאחר הרצת הקוד תראו את התוצאה בפלט מפאנל הקונסולה.
חשוב: לפני שתתחילו להריץ כל פונקציה שהיא, חשוב שתדעו שאם אתם רושמים את סימן השאלה "?" לפני הפונקציה, ייפתח לכם חלון עם הסבר מלא ומפורט על מה שהיא עושה והפרמטרים שלה. לדוגמה:
?t.test()
כמה מילים חשובות על חבילות ב-R
ב-R קיימות מה שנקרא "חבילות / Packages". חבילה זה כמו מאגר של פונקציות שכבר נבנו ומוכנות לשימוש. יש הרבה מאוד חבילות ב-R ואפשר לראות את חלקן בחלון התחתון מצד ימין.
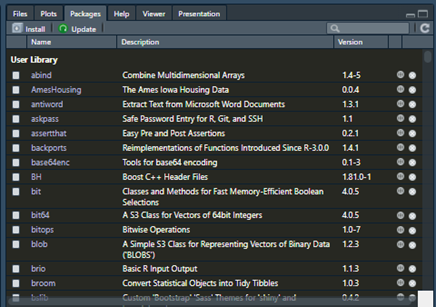
לא תמיד יש מה שאנחנו צריכים כברירת מחדל ב-R, ולכן אנחנו יכולים להוריד חבילה ולהשתמש בפקודות שלה בתוך הקוד שלנו. כשמורידים חבילה היא נשארית בדיסק שלכם, ולא צריך להוריד אותה שוב. יש המון חבילות שימושיות ב-R, יותר מדי מכדי לציין פה את כולן. אתם יכולים להריץ את הפקודה של הורדת חבילות ולראות בעצמכם, בשביל להוריד חבילה יש את הפקודה:
Install.Packages()
אתם יכולים גם לכתוב את שם החבילה בסוגריים ( ) בתוך מירכאות " ". לאחר שהורדתם חבילה, צריך להתקין אותה. בכל פעם שאתם פותחים את R, או מתכוונים להשתמש בחבילה כלשהי אתם חייבים קודם להתקין אותה עם הפקודה הבאה:
Library()
פה לא חובה לרשום את החבילה עם גרשיים.
יצירת וקטורים
יצירת וקטור ב-R הוא תהליך יחסית פשוט. נקח לדוגמא משתנה בשם "X" ונייחס אליו ערך כמותי כלשהו כך:
x <- 5 print(x) 5
סימן ה"->" הוא די אינטואיטיבי כי לא צריך להתבלבל עם מה שהוא עושה. מה שאנו אומרים בזה זה ש-5 כרגע הוא "X", ובכל פעם שנקרא ל"X" נקבל את הערך (או הערכים) שנמצא בו, שהוא 5. אפשר להשתמש בפונקציה של "()print" בשביל לקבל פלט של התוכן של X (אפשר גם פשוט להריץ את שם האובייקט "X"), אבל לא חייב. אפשר גם פשוט לכתוב "X" ולהריץ את הקוד, זה יחזיר לנו אותו הדבר.
דרך קלה להשתמש בפונקציית הייחוס "->" היא ללחוץ על אלט ומינוס (Alt -) בו זמנית.
אז כרגע יצרנו וקטור בשם "X" עם ערך של 5. מה אם נרצה ליצור וקטור עם כמה ערכים? ובכן, אפשר להשתמש בפונקציית combine או בקיצור ()c כדי להכניס מספר ערכים לוקטור כך:
x <- c(1,2,3,4,5) print(x) [1] 1 2 3 4 5
המספר בסוגריים המרובעים [1] מסמל את מספר המיקום של הערך. סוג הנתונים יכול להיות גם איכותני. נניח שאנחנו רוצים 3 שמות בתוך וקטור. כל שם יהיה בתוך מירכאות, ומופרד בפסקות כך:
X <- c(“אלכס”,”שמואל”,”יוסי”) X [1] "יוסי" "שמואל" "אלכס"
כרגע לצורך הפשטות, נתמקד בעיקר בנתונים כמותיים. אם היינו הופכים את הוקטור "X" למטריצה באמצעות הפונקציה ()matrix, היינו אז רואים 5 שורות לכל ערך, וכולם בעמודה הראשונה:
x <- matrix(x) print(x) [,1] [1,] 1 [2,] 2 [3,] 3 [4,] 4 [5,] 5
מה אם אנחנו רוצים להוסיף עוד עמודה למטריצה? בואו נוסיף עוד משתנה בשם Y עם ערכים שונים, ונאחד אותו למשתנה אחד בשם "XY".
x <- c(1,2,3,4,5) print(x) [1] 1 2 3 4 5 y <- c(6,7,8,9,10) print(y) [1] 6 7 8 9 10 xy <- c(x,y) print(xy) [1] 1 2 3 4 5 6 7 8 9 10
ועכשיו בואו ניצור מטריצה מ"XY":
mymatrix <- matrix(xy, nrow = 10, ncol = 1) print(mymatrix) [,1] [1,] 1 [2,] 2 [3,] 3 [4,] 4 [5,] 5 [6,] 6 [7,] 7 [8,] 8 [9,] 9 [10,] 10
עכשיו יש לנו מטריצה. המספרים בסוגריים אומרים לנו על מספר השורות והעמודות, והפסיק מסמל על השורה או העמודה. פסיק אחרי המספר אומר שזו שורה, ופסיק לפני המספר אומר שזו עמודה. מספר בסוגריים שאינו מכיל פסיקים, פשוט אומר על המיקום בסדר הנתונים.
מה אם נרצה לשים רק את "X" בעמודה הראשונה ואת "Y" בעמודה השניה? נעשה את זה כך:
נשתמש בפרמטרים "nrow", "ncol" ו-"byrow", שהם כולם פרמטרים של הפונקציה ()matrix.
nrow הוא פרמטר שאומר לפונקציה בכמה שורות לבנות את המטריצה. אם יש לנו 5 ערכים, אז נרצה 5 שורות.
ncol הוא פרמטר שאומר לפונקציה בכמה עמודות לבנות את המטריצה. אנו רוצים 2 עמודות.
byrow הוא פרמטר שאומר לפונקציה באיזה סדר לסדר את הנתונים שלנו במטריצה. אם הארגומנט שלנו הוא "TRUE", אז הנתונים יסתדרו לפי שורות, ואם הארגומנט הוא "FALSE", אז הנתונים יסתדרו לפי עמודות. אנחנו רוצים לסדר את הנתונים שלנו (X+Y) בסדר של עמודות. כלומר, שה-5 הערכים הראשונים ימלאו את העמודה הראשונה, וה-5 נוספים את העמודה אחריה.
ככה תראה הפונקציה שלנו:
mymatrix <- matrix(xy, nrow = 5, ncol = 2, byrow = FALSE)
וזה יראה ככה:
mymatrix <- matrix(xy, nrow = 5, ncol = 2, byrow = FALSE) print(mymatrix) [,1] [,2] [1,] 1 6 [2,] 2 7 [3,] 3 8 [4,] 4 9 [5,] 5 10
אפשר גם להכניס לתוך המטריצה וקטורים שונים שאינם מאוחדים עם פונקציית ()cbind כך:
mymatrix <- cbind(x,y) print(mymatrix) [,1] [,2] [1,] 1 6 [2,] 2 7 [3,] 3 8 [4,] 4 9 [5,] 5 10
עכשיו זה נראה כמו טבלה רגילה וחביבה שאנו מכירים, אבל אל תשכחו שהמטריצה מכילה רק סוג אחד של מידע, במקרה הזה ערכים כמותיים. אפשר לבדוק איזה סוג מידע מכילה המטריצה שלנו עם הפונקציה mode():
mode(mymatrix) [1] "numeric"
יצירת מסגרות נתונים
כדי ליצור מהמטריצה שלנו מסגרת נתונים, נשתמש בפונקציה ()as.data.frame כדי להפוך אובייקט למסגרת נתונים.
mydata <- as.data.frame(mymatrix) mydata x y 1 1 6 2 2 7 3 3 8 4 4 9 5 5 10
אפשר להשתמש גם בפונקציה לבדה, ()data.frame ואז להכניס בה את הארגומנטים של "X" ו-"Y":
x <- c(1:5) y <- c(6:10) data.frame(x,y) x y 1 1 6 2 2 7 3 3 8 4 4 9 5 5 10
כעת אנו יכולים להשתמש בפונקציה ()View (שימו לב לאות הגדולה) כדי להסתכל ויזואלית על מסגרת הנתונים:
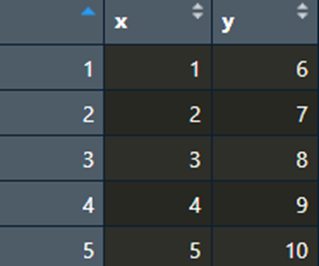
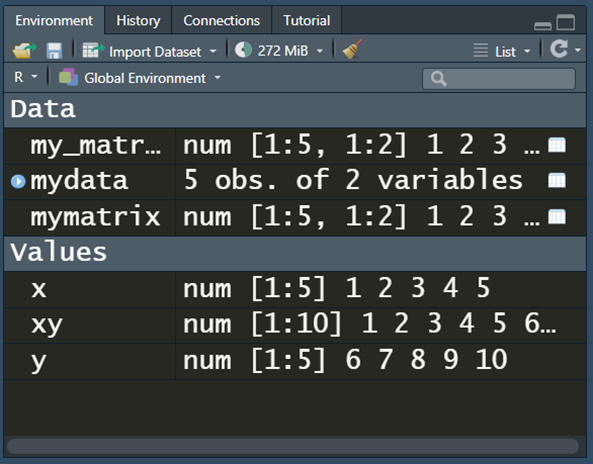
אנחנו יכולים להגיע לאותו הצג גם באמצעות לחיצה על mydata בחלון ה-Environment:
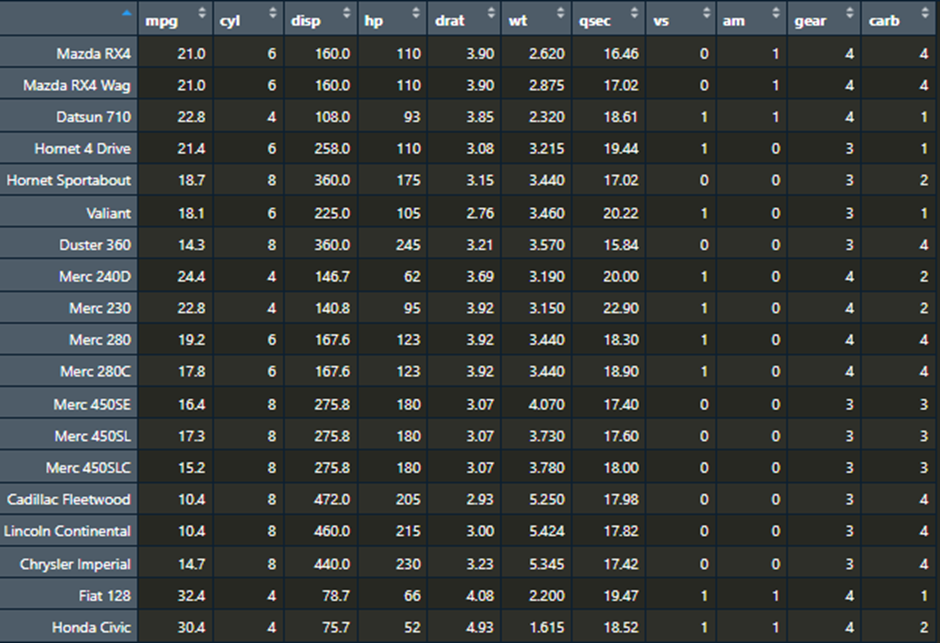
יש פונקציה בשם ()head שנותנת לנו לראות את ה-5 שורות הראשונות של כל העמודות במסגרת הנתונים שלנו. נשתמש לדוגמא במסגרת נתונים שהיא כבר בנויה לתוך R הנקראת "mtcars". נכניס את מסגרת הנתונים ל-Environment שלנו ככה:
mtcars <- mtcars View(mtcars)
וכך נראת מסגרת הנתונים:
אם כעת נשתמש בפונקציית ה-()head אנו נראה פלט מקוצר של מסגרת הנתונים:
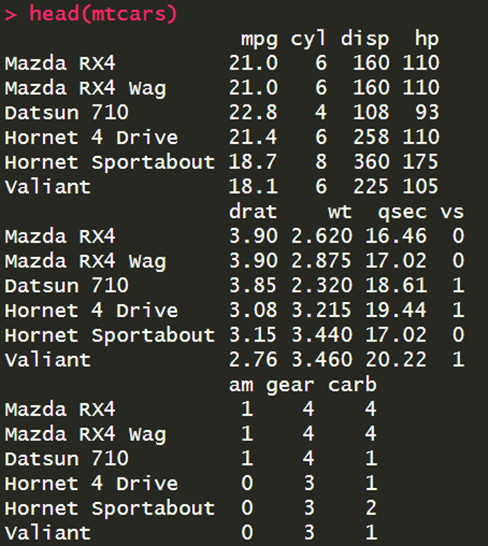
יש פונקציה שעושה את אותו הדבר, רק מה-5 השורות האחרונות במסגרת הנתונים, וקוראים לה ()tail.
חלק 2: סטטיסטיקה
יש פונצקיה בשם ()summary שהיא מאוד שימושית. מה שהיא עושה זה לוקחת את הארגומנט (במקרה זה מסגרת הנתונים שלנו) ונותנת לנו סטטיסטיקה תיאורית לגבי כל עמודה.
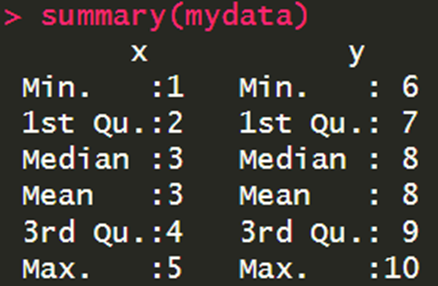
פה אנחנו יכולים לראות מדדים כמו מינימום, מקסימום, חציון, ממוצע, וטווח בין רבעוני. יש פונקצייה שיכולה לעשות סכום למשל ()sum או ממוצע למשל ()mean.
x [1] 1 2 3 4 5 mean(x) [1] 3 sum(x) [1] 15
את שניהן אפשר לבצע על אותה שורה במספר עמודות:
mydata x y 1 1 6 2 2 7 3 3 8 4 4 9 5 5 10 sum(mydata[1,]) [1] 7
אפשר גם להפיק סכום מכל השורות באמצעות פונקצייה אחרת ()rowSums או ()colSums.
mydata x y 1 1 6 2 2 7 3 3 8 4 4 9 5 5 10 rowSums(mydata) [1] 7 9 11 13 15
באותה מידה אפשר לעשות אותו הדבר עם ממוצעים באמצעות ()rowSums או ()colSums.
mydata x y 1 1 6 2 2 7 3 3 8 4 4 9 5 5 10 rowMeans(mydata) [1] 3.5 4.5 5.5 6.5 7.5
אבל מה אם רוצים לעשות עמודה חדשה שתכיל רק את הממוצעים או הסכומים? אפשר ליצור עמודה חדשה במסגרת הנתונים עם כל פונקציה. מה שצריך לעשות זה לרשום את אובייקט מסגרת הנתונים ולהוסיף אליו סימן דולר $, ואז שם חדש לעמודה.
mydata$means <- rowMeans(mydata) mydata x y means 1 1 6 3.5 2 2 7 4.5 3 3 8 5.5 4 4 9 6.5 5 5 10 7.5
סימן הדולר הוא מה ש"מסמן" את מה בדיוק אנו רוצים לקחת ממסגרת הנתונים. דרך קיצור לסימון של עמודה לפי השם שלה אם הוא קיים. אפשר להשתמש גם בסוגריים מרובעות [].
mydata$means [1] 3.5 4.5 5.5 6.5 7.5 mydata[,3] [1] 3.5 4.5 5.5 6.5 7.5
אפשר גם לסמן מספר עמודות או שורות ביחד:
mydata x y means 1 1 6 3.5 2 2 7 4.5 3 3 8 5.5 4 4 9 6.5 5 5 10 7.5 mydata[c(1,3),] x y means 1 1 6 3.5 3 3 8 5.5
הדבר הנפלא ב-R הוא שאפשר לעשות טרנספורמציות מאוד קלות על הנתונים. נגיד ונרצה לעשות פונקציה מתמטית על 2 עמודות. למשל לעשות חילוק בין "X" ל-"Y", ואז לייחס את זה לעמודה שלישית חדשה.
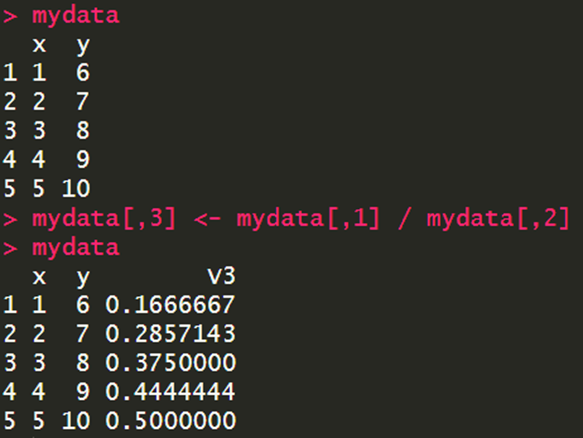
עכשיו בואו נניח שאנחנו רוצים לבדוק אם יש קשר סטטיסטי בין 2 סדרות נתונים. הפקודה של מתאם היא ()cor.
x <- c(1,2,3,4,5) y <- c(5,4,3,2,1) cor(x, y, method = "pearson") [1] -1
אנחנו יכולים להגיד ל-R באיזה סוג מבחן קשר להשתמש.
מה אם אנחנו רוצים לבדוק אם יש הבדל בין 2 עמודות? נשתמש למשל במבחן טי עם הפקודה ()t.test.
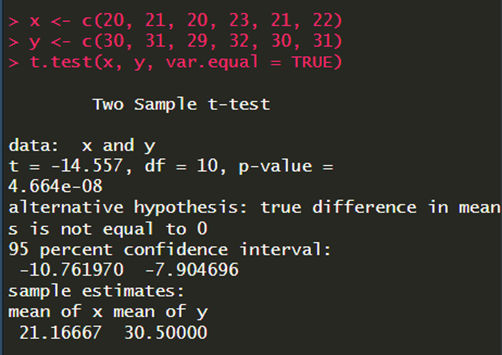
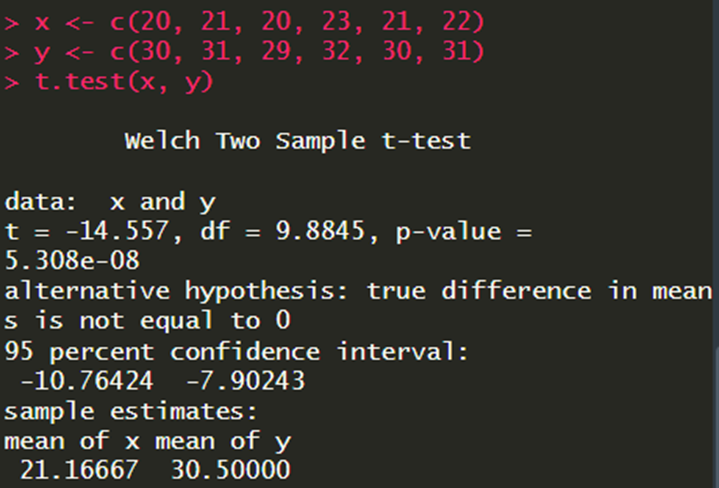 שימו לב: ברירת המחדל היא להשתמש במבחן Welch, שהוא מבחן סטטיסטי כמו מבחן טי כשאין הנחה של שוויון שונויות. בשביל להשתמש בטי רגיל, אתם צריכים לציין זאת בפונקציה: var.equal = TRUE
שימו לב: ברירת המחדל היא להשתמש במבחן Welch, שהוא מבחן סטטיסטי כמו מבחן טי כשאין הנחה של שוויון שונויות. בשביל להשתמש בטי רגיל, אתם צריכים לציין זאת בפונקציה: var.equal = TRUE
לדוגמה:
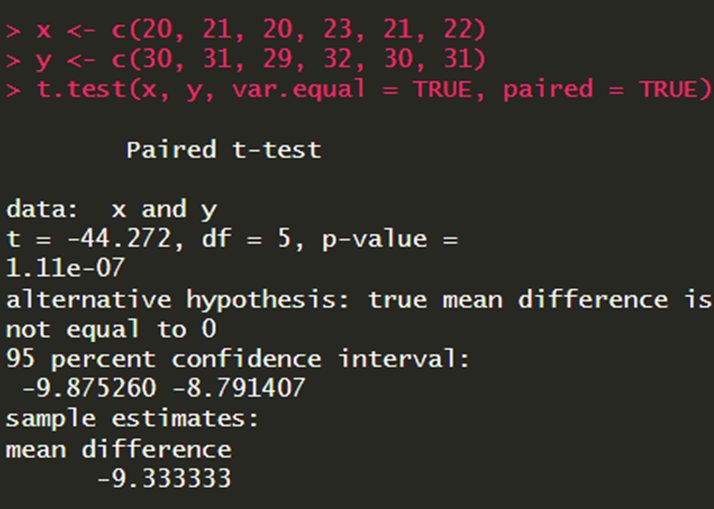
אם אתם רוצים לעשות מבחן טי למדגמים תלויים, אתם חייבים לציין זאת גם:
שימו לב: ברירת המחדל של R כשהיא מציגה ערכי מובקות (p-values) היא להציג אותם בתור פורמט אקספוננציאלי, למשל ככה:
1.11e-07
מה שזה אומר לנו זה שיש שבע אפסים, ואז את המספר 1.11, כלומר – 0.000000111
אנחנו יכולים לשנות את ההצגה הזו של ערכי מובהקות עם הפוקדה הבאה:
options(scipen = 999, digits = 10)
לבסוף נציג איך מבצעים רגרסיה ביתר קלות ב-R. נגיד יש לנו כמה משתנים: X, a, b, c, ואנחנו רוצים לנבא את X באמצעות שאר המשתנים. נשתמש בפקודה ()lm (אות L קטנה):
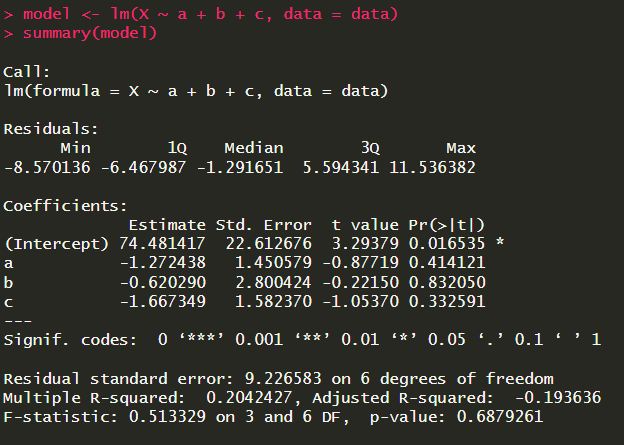
שימו לב: לא נשתמש בפקודה ()print בשביל לראות את נתוני הרגרסיה, כי הפקודה הזו רק תביא לנו את מקדמי הרגרסיה, ולא את שאר הנתונים. בשביל לראות את התיאור של כל המודל נשתמש בפקודה ()summary.
אלו הם רק כמה דרכים להשתמש ב-R בשביל תכנות סטטיסטי, וכאן הראתי רק את אבני היסוד. אפשר לעשות הרבה יותר עם תכנות סטטיסטי ולצערי הנושא הזה לא יספיק להיקף הבלוג הזה.
חלק 3: גרפים
זה הוא החלק האהוב עליי ב-R. אתם יכולים ליצור כל גרף שאתם יכולים רק לדמיין עם הרבה חבילות שנבנו רק בשביל זה (למשל ggplot). לראות את הנתונים בגרף במקום במספרים זה הרבה יותר קל, תאמינו לי. זה גם מאפשר לנו לקחת הפסקה ולחשוב קצת מחוץ לקופסא, לראות את התמונה הגדולה.
Scatterplot
הפקודה לגרף סקאטר (גרף שמשתמשים בו הרבה בשביל לתאר יחס בין 2 משתנים, למשל בשביל לראות אם יש מתאם) היא ()plot. לפקודה זו מוסיפים כמה ארגומנטים חשובים בשביל לקבוע איזה סוג גרף זה יהיה. פרמטר ה"pch" הוא פרמטר שמשנה את הצורה של הנתונים. אתם יכולים לשחק עם זה ולראות איזה סוגים יש.
plot(x, y, main = "כותרת", xlab = "ציר איקס", ylab = "ציר ווי", pch = 19, col = "blue")
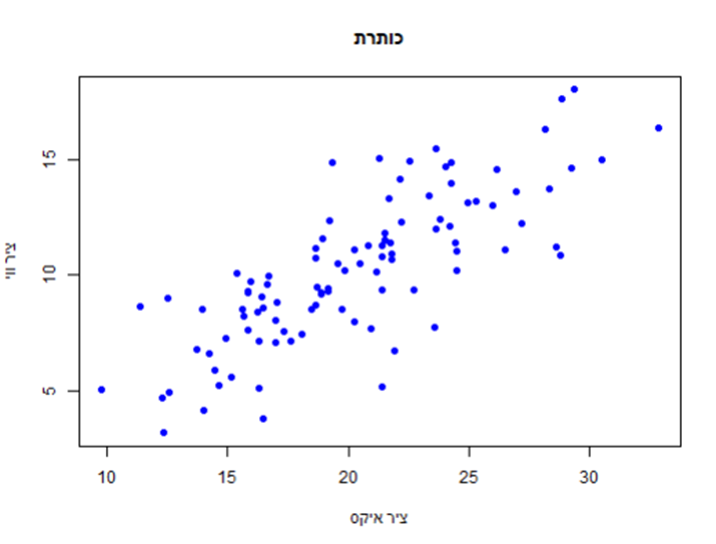
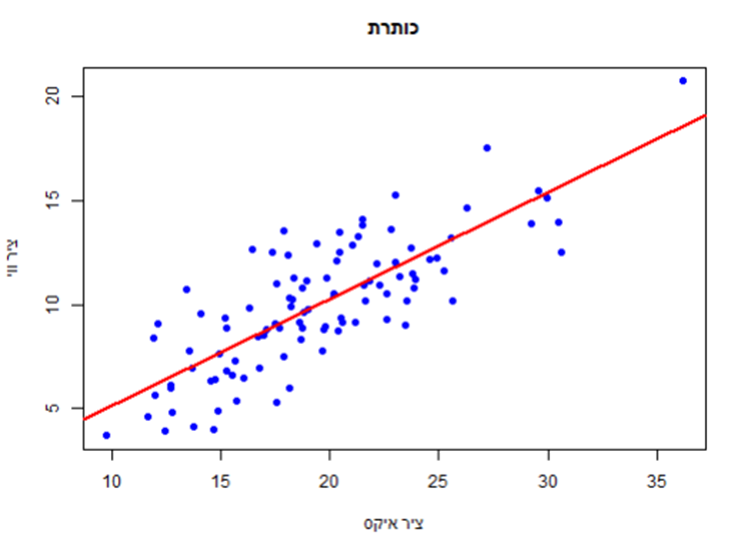
אנחנו יכולים גם להוסיף לו קו ניבוי באמצעות פונקציית רגרסיה ()lm, ככה:
model <- lm(y~x)abline(model, col = "red", lwd = 2)
היסטוגרמה
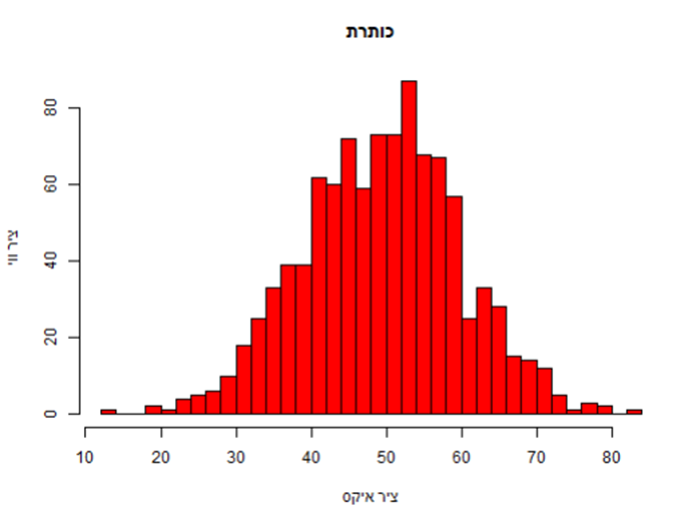
משתמשים בהיסטוגרמה בדרך כלל בשביל לראות את שכיחות הנתונים של משתנה אחד.
hist(data, main = "כותרת", xlab = "ציר איקס", ylab = "ציר ווי", col = "red", breaks = 30)
קופסאות
גרף קופסא בדרך כלל נותן לנו לראות כמה דברים: החציון הוא הקו בתוך הקופסא. השטח הצבוע של הקופסא הוא הטווח הבין רבעוני (כלומר, מה-25% עד ה-75% העליונים). ה"שיערות" או הקווים מחוץ לשטח הצבוע מקיפים בערך 99.3% מהנתונים. אם אנחנו רואים חוסר סימטריות (למשל קופסא שהיא קרובה יותר לחלק התחתון או העליון של הקצה, או חציון שהוא לא באמצע) זה יכול להעיד משהו על הנורמליות של הנתונים.
boxplot(x, y, names = c("X", "Y"), main = "כותרת", col = c("orange", "red"))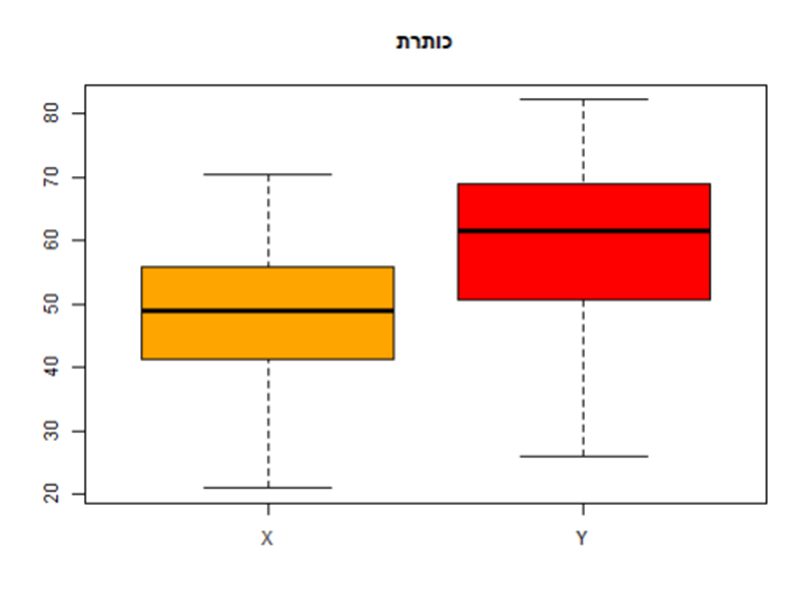
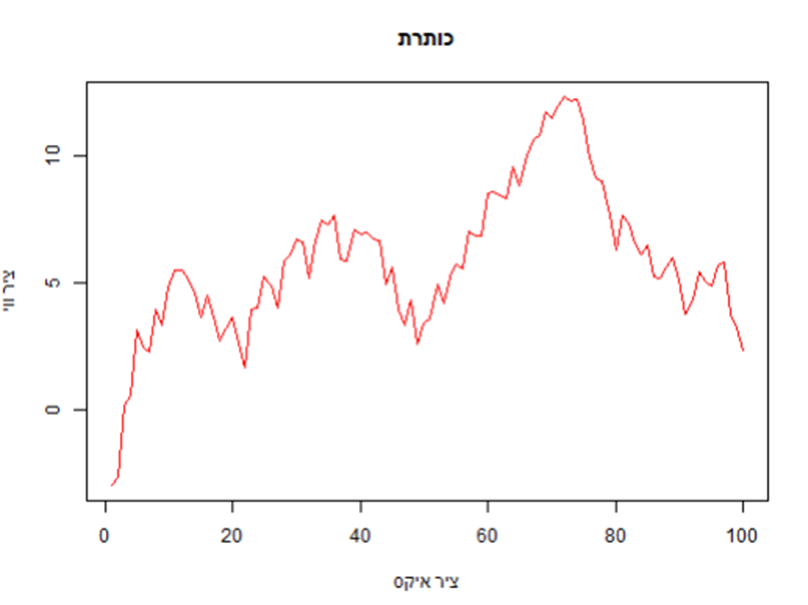
גרף קווי
מתאים כשאנחנו רוצים לתאר שינוי כלשהו בזמן. גם את הגרף הזה בונים עם הפונקציה של ()plot.
plot(x, y, type = "l", main = "כותרת", xlab = "ציר איקס", ylab = "ציר ווי", col = "red")
Ggplot2
החבילה הזו היא מסגרת לבניית גרפים, והיא מאוד מגוונת. אפשר לעשות בה את כל מה שעשינו למעלה, ואף יותר. צריך להתקין את החבילה הזו כל פעם שאנו רוצים ליצור איתה גרפים. בבלוג הזה לא נכנס לפקודות של ggplot, כי אפשר לכתוב ספר שלם רק על זה. אבל, אני עדיין רוצה להראות כמה דוגמאות רק בשביל שתראו מה אפשר לעשות עם זה.
כמה דוגמאות לגרפים:

חלק 4: ספרים ומקורות נוספים
- "R For Data Science" מאת Hadley Wickham
- "Advanced R" מאת Hadley Wickham
- "The Book of R: A First Course in Programming and Statistics" מאת Tilman Davies
- "The Art of R Programming" מאת Norman Matloff
- "Machine Learning with R" מאת Brett Lantz
סיכום
אני מקווה שהבלוג פוסט הזה יעזור לכמה אנשים, או לפחות יפתח להם כיוון מעניין לשפה חדשה, אם כבר יש להם נסיון בתכנות. בתכלס, בשביל מי שעוסק עם נתונים הכלי הזה יכול להיות נורא שימושי. במיוחד למי שעובד עם נתונים, אם זה סטודנט שעובד עם נתוני מחקר או בן אדם שעובד עם קבצי אקסל במשאבי אנוש או כל תחום אחר, אתם יכולים לעשות את אותו הדבר, באופן אוטומתי, בפי 5 פחות זמן.
תלוי בביקוש, אני אולי אמשיך לכתוב בלוגים על תכנות ספציפית עם R כי יש עוד המון דברים מעניינים שאפשר לעשות עם זה.
תודה על הקריאה.