מה זה למידת מכונה? המדריך המלא לכל מי שלא מתכנת
הפוסט הזה יתמקד בלמידת מכונה, בעיקר בשביל אנשים שלא יודעים או מבינים בתכנות (או בסטטיסטיקה). הפוסט מופנה גם לסטודנטים, גם לחוקרים, גם לאנשים בתחום ההיי-טק וגם לאנשים שזה סתם מעניין אותם.
מבוא ללמידת מכונה – למה זה חשוב?
למידת מכונה היא תחום במדעי המחשב ובינה מלאכותית, בין היתר, המתמקד בפיתוח אלגוריתמים ומערכות שמסוגלות ללמוד מתוך נתונים ולשפר ביצועים באופן עצמאי, ללא צורך בתכנות מפורש עבור כל משימה.
זאת אומרת, בואו נקח לדוגמא מכונה שלומדת לזהות אובייקטים. אתם ודאי מכירים כשהסמארטפון שלכם מזהה פנים של בן אדם כשהם מצלמים איתו. זה בדיוק למידת מכונה. בסמארטפון יש תוכנה חכמה שיודעת ללמוד ולנבא מתי הנתונים שהיא מקבלת מהסנסור של המצלמה מתאימים לדפוס של פנים.
באמצעות זיהוי דפוסים, ניתוח מידע והתאמה חוזרת, מערכות כאלה מסוגלות לבצע ניבויים, סיווגים או קבלת החלטות מדויקת יותר ככל שהן "נחשפות" ליותר נתונים. מזכיר לכם מודלי רגרסיה? כי זה בדיוק זה - רק אוטומטי ומשוכלל יותר.
דוגמאות נפוצות לשימושים בלמידת מכונה כוללות זיהוי דיבור ותמונות, מנועי חיפוש, המלצות תוכן מותאמות אישית, זיהוי הונאות פיננסיות ואף כלי רפואה מתקדמים המסייעים באבחון מחלות (כמו למשל אלצהיימר, פרקינסון ועוד).
התחום מהווה חלק חשוב בהתפתחות טכנולוגיות מתקדמות כמו כלי רכב אוטונומיים, רובוטיקה וניתוח ביג דאטה. בנוסף, התחום הזה מתפתח גם במחקר כיום בתחומים רפואיים וטיפוליים אחרים כמו נוירולוגיה, קוגניציה ופסיכולוגיה.
סוגי למידת מכונה – מבוקרת מול לא מבוקרת
למידת מכונה מבוקרת
למידה מבוקרת (Supervised Learning) היא סוג של למידת מכונה שבה האלגוריתם לומד מתוך מערך נתונים מתויג, כלומר, כל דגימת נתונים כוללת תשובה נכונה (label). לדוגמא: יש לנו מינון של תרופה (שאלה) ותוצאת הטיפול (תשובה). בעצם, כאן תפקיד הלמידה הוא ללמוד מנתונים נכנסים (קלט) ולנבא את הנתונים היוצאים (הפלט). בדוגמא שלנו היינו רוצים להבין, איך מינון מסוים של תרופה ישפיע על תוצאות הטיפול.
לדוגמה, אם נרצה ללמד מודל לזהות תמונות של פטריות רעילות ולא רעילות, נספק למערכת אוסף של תמונות של פטריות יחד עם סיווג ("רעילה" או "לא רעילה"). האלגוריתם ישתמש בדוגמאות הללו כדי ללמוד את ההבדלים ולהעריך סיווגים עבור תמונות חדשות.
מטרת האלגוריתם היא ללמוד את הקשר בין הנתונים לבין התשובות הנכונות כדי שיוכל לחזות תשובות חדשות על סמך נתונים לא מוכרים. זאת אומרת, נכנס אלינו מטופל חדש ואנחנו לא יודעים איך התרופה תשפיע עליו אבל אנחנו יכולים לנבא את ההשפעה באמצעות מה שהמכונה למדה על נתונים קודמים.
למידת מכונה לא מבוקרת
למידה לא מבוקרת (Unsupervised Learning), לעומת זאת, מתבצעת ללא תוצאות או סיווג ברור בנתונים. כאן, האלגוריתם מנסה לזהות תבניות וקשרים בתוך הנתונים באופן עצמאי ולסווג את הדוגמאות לקבוצות על פי מאפיינים משותפים. למי שמכיר, זה כמו סוג של ניתוח גורמים חקרני (Explorative Factor Analysis).
לדוגמה, אם נזין למודל אוסף של תמונות של פטריות מבלי לספק לו מידע מקדים על סוגי הפטריות, המודל יוכל לזהות קבוצות של פטריות בעלות מאפיינים דומים (כמו צורה וצבע), אך לא ידע להגדיר מה משמעות הקבוצות. סוג זה של למידה מתאים למשימות כמו זיהוי קבוצות לקוחות דומות לשיווק מותאם אישית או גילוי אנומליות במידע, כמו איתור פעילות חריגה בחשבון בנק, או דפוסים יוצאי דופן של תנועות עיניים לפי קבוצות שונות של אנשים.
איך למידת מכונה יכולה לעזור לכם
למידת מכונה מחוללת מהפכה בתחומי ידע רבים בכך שהיא מאפשרת לנתח כמויות עצומות של נתונים, לחשוף דפוסים חבויים ולספק תחזיות מדויקות. בנוירולוגיה וברפואה למשל, משתמשים באלגוריתמים כדי לנתח נתוני גלי מוח (EEG) ודימות מוחי כמו MRI בשביל לאתר מוקדם מצבים רפואיים כגון גידולים, אפילפסיה ומחלות נוירו-דגנרטיביות כמו אלצהיימר.
מערכות למידת מכונה מסוגלות לזהות שינויים קטנים או דפוסים מורכבים שקשה מאוד לזהות באופן ידני, ובכך לסייע בקבלת אבחנות מדויקות יותר. בנוסף, בריאות הנפש נהנית משיפורים משמעותיים בזכות כלים טכנולוגיים שמסייעים בזיהוי מוקדם של דיכאון, חרדה ואף מחשבות אובדניות באמצעות ניתוח שפה, קול ודפוסי שימוש דיגיטלי.
גם בתחום הכלכלה, למידת מכונה מספקת יכולות ניבוי מתקדמות שמאפשרות זיהוי מגמות בשוק, תחזיות מדויקות לגבי השקעות וניתוח התנהגויות צרכן מורכבות. כך, ניתן לקבל החלטות מבוססות נתונים לגבי תמחור, תכנון פיננסי והתמודדות עם משברים.
גם במדעי החברה ופסיכולוגיה יש ללמידת מכונה מקום משמעותי, שכן היא מאפשרת לנתח תוצאות של סקרים וראיונות בצורה שמגלה דפוסים בלתי צפויים ומאפשרת הבנה עמוקה יותר של התנהגויות אנושיות. הטכנולוגיה הזו משמשת גם בפיתוח צ'טבוטים טיפוליים שמסייעים למטופלים בגישה נוחה ומותאמת אישית ובמערכות שמנטרות שינויים במצב הרוח לאורך זמן ומספקות התראות כאשר יש שינוי מדאיג.
הסיבה לכך שהיום מלמדים פסיכולוגים תכנות נובעת מהצורך שלהם לנתח מאגרי נתונים גדולים בעצמם ולבנות כלים מותאמים למחקר ולטיפול. ידיעת תכנות פותחת עבור רבים מהם דלת לעולם חדש שבו ניתן לבצע ניסויים גדולים יותר, לעבד נתונים התנהגותיים באופן עצמאי ולהשתמש באלגוריתמים שמבצעים עיבוד שפה, זיהוי רגשות וניתוח דפוסים בזמן אמת.
ידע זה מאפשר לפסיכולוגים לעבור ממחקר המתמקד במדגמים קטנים לעבודה עם נתונים שמגיעים ממיליוני משתמשים ולשפר את הבנתם לגבי מנגנונים פסיכולוגיים בקנה מידה רחב ומדויק יותר. כך, הם יכולים להשתלב בתחומי מחקר רחבים יותר ולהציע פתרונות מדעיים מבוססי נתונים שלא רק מעמיקים את המחקר אלא גם מייעלים את שיטות הטיפול בפועל.
איך אלגוריתמים פועלים: רגרסיות, עצים וחיזוקים
למידה מבוקרת
רגרסיה לינארית
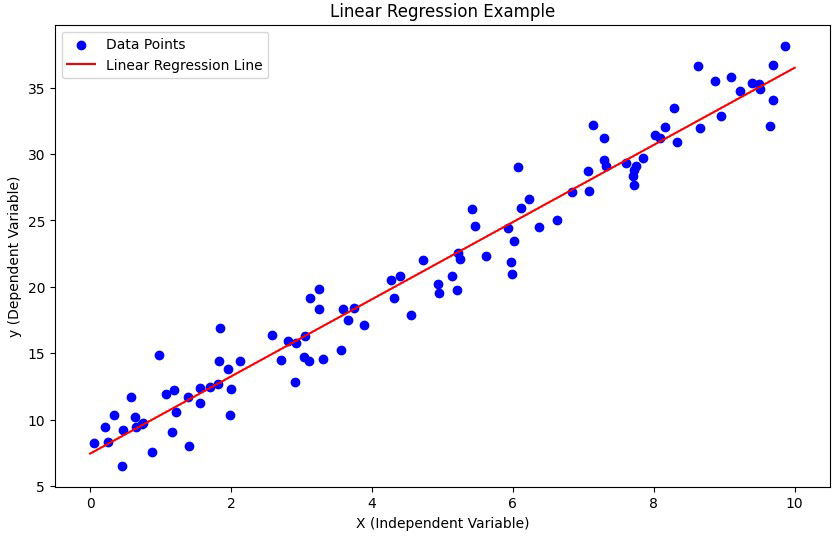
רגרסיה לינארית היא אחת השיטות הבסיסיות והנפוצות ביותר בלמידת מכונה ומשמשת לניבוי ערכים רציפים. בשיטה זו, המודל לומד לזהות את הקשר הלינארי בין משתני הקלט (כגון מיקום, גודל הדירה ומספר החדרים) לבין התוצאה (למשל, מחיר הדירה).
לדוגמה, אם רוצים לנבא מחיר של דירה בתל אביב, המודל יקבל נתונים על דירות קודמות ויחשב "קו ישר" שמייצג את הקשר בין הנתונים למחירים. דוגמה נוספת היא תחזית מזג אוויר: אם ננתח נתוני עבר של טמפרטורות, לחות וכמות עננים, רגרסיה לינארית יכולה להציע תחזית ליום המחרת. כך, שיטה זו מאפשרת לנו להבין מגמות ולחזות משתנים עתידיים על בסיס נתונים קיימים בצורה פשוטה אך יעילה.
ברמה הפשוטה, הרגרסיה מחשבת "שיפוע" שמראה כמה המחיר משתנה בהתאם לשינוי באחד מהמשתנים. ברמה מורכבת יותר, היא ממזערת את ההבדל (שגיאה) בין התחזיות לערכים האמיתיים על ידי אופטימיזציה של הפונקציה המתמטית.
ברגרסיה לינארית, המטרה היא למצוא קו ישר שמתאר בצורה הטובה ביותר את הקשר בין הנתונים לבין הערכים שאנחנו רוצים לנבא. בפועל, המודל מנחש ערכים על סמך הקלט, אבל הניחוש הזה לא תמיד מדויק. כדי לשפר את הדיוק, המודל משווה את התחזיות שלו לערכים האמיתיים מהנתונים ומחשב את ההפרש ביניהם – זה מה שנקרא "שגיאה".
השגיאה נמדדת לרוב באמצעות פונקציה שנקראת פונקציית עלות (Loss Function), שבדרך כלל סוכמת את ריבועי ההבדלים בין התחזיות לערכים האמיתיים (Mean Squared Error - MSE). למה דווקא ריבוע ההבדל? כדי להפוך את כל ההבדלים לחיוביים (שלא יהיו מספרים שליליים) ולהדגיש יותר שגיאות גדולות.
האופטימיזציה היא התהליך שבו המודל מעדכן שוב ושוב את השיפוע והחיתוך של הקו, כך שפונקציית העלות תהיה קטנה ככל האפשר – כלומר, שהשגיאות יהיו מינימליות. התהליך הזה מתבצע בעזרת שיטה שנקראת גרדיאנט ירידה (Gradient Descent), שבה המודל "מטפס במורד ההר" של פונקציית העלות עד שהוא מוצא את הנקודה שבה ההפרשים הם הכי קטנים שאפשר. בצורה הזו, המודל מוצא את הקו הטוב ביותר שינבא באופן המדויק ביותר את הערכים הרצויים.
עצי החלטה (Decision Trees)
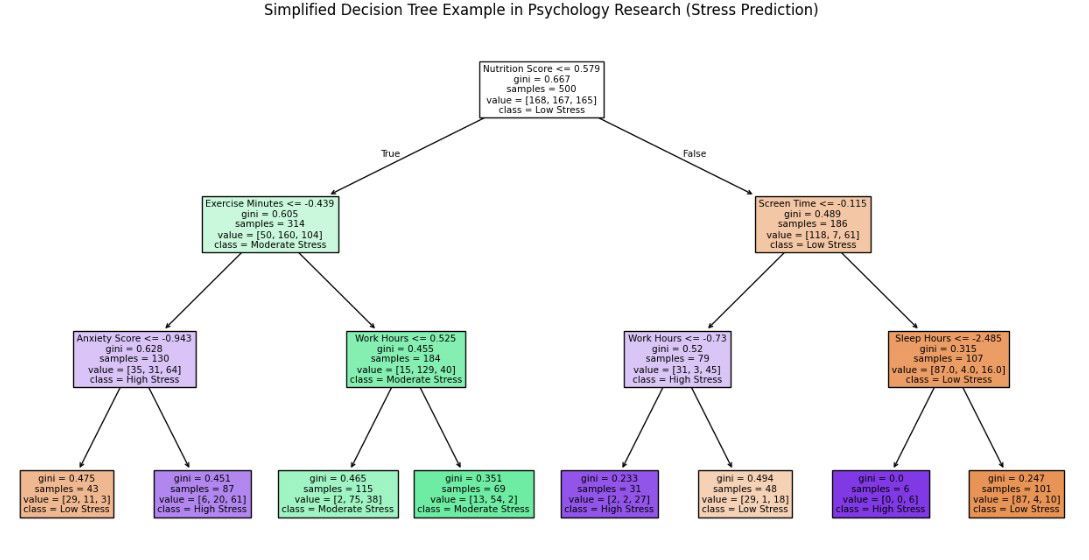
עצי החלטה (Decision Trees) הם מודלים בלמידת מכונה המדמים תהליך קבלת החלטות בצורה היררכית, ממש כמו תרשים זרימה. המודל בוחן כל פעם תכונה אחת של הנתונים ומחלק אותם לצמתים בהתאם לערכים שלה, עד שהוא מגיע להחלטה סופית.
ברמה הפשוטה, ניתן לחשוב על עץ החלטה כמו שאלון "כן או לא": נניח שאנחנו רוצים לנבא אם אדם יאהב סרט מסוים. השאלה הראשונה בעץ יכולה להיות "האם הסרט הוא פעולה?" אם כן – נעבור לשאלה הבאה: "האם יש שחקן מוכר?" אם לא – אולי נגיע ישר להחלטה הסופית ("לא צפוי לאהוב").
ברמה המורכבת יותר, המודל בוחר אילו שאלות לשאול בכל צומת על סמך מידת התרומה שלהן להקטנת חוסר הוודאות – כלומר, כמה כל תכונה עוזרת להפריד טוב יותר בין הקבוצות השונות של הנתונים.
במודלים של עצי החלטה, בכל שלב שבו המודל צריך להחליט איזו שאלה לשאול (או באיזו תכונה להשתמש כדי לחלק את הנתונים), הוא מחפש את השאלה שתקטין בצורה המיטבית את חוסר הוודאות לגבי התוצאה הסופית. אבל איך הוא מחליט מהי השאלה הטובה ביותר? כאן נכנסים לתמונה מדדים מתמטיים שמעריכים את "איכות הפיצול".
המודל משתמש במדדים כמו אנטרופיה או מדד ג'יני כדי להעריך את הפיצול.
- אנטרופיה: מודדת את מידת האי-סדר בקבוצה. אם הקבוצה מכילה תערובת שווה של קטגוריות (למשל, חצי "כן" וחצי "לא"), היא תהיה במצב של אי-סדר גבוה (אנטרופיה גבוהה). ככל שהקבוצה הופכת להומוגנית יותר (קרובה ל-100% "כן" או "לא"), האנטרופיה שלה יורדת.
- מדד ג'יני: מודד עד כמה החלוקה "נקייה". אם אחרי הפיצול כל תת-קבוצה מכילה רק סוג אחד של תוצאה (למשל, רק "כן" או רק "לא"), המדד יהיה נמוך מאוד (שואף לאפס), וזה מה שהמודל רוצה להשיג.
נניח שאנחנו רוצים לנבא אם תלמיד יעבור מבחן על סמך מספר שעות הלמידה והאם הוא ישן טוב בלילה שלפני.
- השאלה הראשונה יכולה להיות: "האם התלמיד ישן לפחות 6 שעות?" אם כן, נמשיך לשאלה אחרת (למשל, מספר שעות הלמידה).
- הפיצול הזה ייחשב טוב אם אחרי החלוקה נקבל קבוצות שבהן תלמידים שישנו טוב לרוב עוברים את המבחן, והקבוצות של אלה שישנו מעט לרוב לא עוברים.
המטרה היא לבחור בכל צומת את התכונה שתיצור חלוקה שבה הקבוצות הפנימיות הן כמה שיותר "טהורות" – כלומר, כל תת-קבוצה תהיה כמה שיותר קרובה לתוצאה אחידה. ככל שהחלוקה יותר "נקייה", המודל מקבל החלטות מדויקות יותר, וכך הוא ממזער טעויות בהמשך הדרך.
לכן, בראייה מורכבת יותר, המודל בעצם עורך "סינון" בין כל התכונות הנתונות ושואל את עצמו: "איזו מהן הכי עוזרת לי לצמצם את הערפל ולהגיע להחלטה ברורה?" כל תכונה נמדדת לפי התרומה שלה לשיפור הדיוק של התחזית, והמודל בוחר תמיד בפיצול שיוביל לירידה המרבית בחוסר הוודאות.
האופטימיזציה מתבצעת כך שהעץ ימשיך להתפצל בצורה יעילה עד שההחלטות בצמתים הסופיים יהיו כמה שיותר חד-משמעיות. בסופו של דבר, עץ ההחלטה מאפשר לנו להסיק תובנות מורכבות מהנתונים בצורה קלה להבנה ויזואלית, כמו להסתכל על תהליך בחירה שמחולק לשלבים ברורים – בדיוק כמו לקחת בחירות גדולות ולפרק אותן לצעדים קטנים ומסודרים.
SVM (Support Vector Machines)
אלגוריתם SVM (Support Vector Machines) הוא אחד הכלים החזקים והמתוחכמים ביותר לסיווג נתונים בלמידת מכונה. המטרה שלו היא למצוא קו גבול (Hyperplane) שמפריד בין הקבוצות בצורה הכי טובה שאפשר, כלומר, בצורה שבה המרחק בין הקו לבין הנתונים הקרובים ביותר מכל צד – יהיה הכי גדול שאפשר. זה מבטיח שההפרדה תהיה יציבה גם כשמתווספים נתונים חדשים.
תאר לעצמך שיש לך שני סוגי נקודות על דף – עיגולים ומשולשים – ואתה רוצה לצייר קו שמפריד ביניהם כך שכל העיגולים יהיו בצד אחד של הקו וכל המשולשים בצד השני. עכשיו, נניח שיש כמה דרכים לצייר קו כזה – אבל איזה קו עדיף?האלגוריתם SVM בוחר את הקו שמותיר את המרווח (Margin) הגדול ביותר בין הקו לבין הנקודות הכי קרובות אליו מכל צד. כך, גם אם הנתונים "יזוזו" מעט, ההפרדה עדיין תישאר טובה.
איך זה עובד ברמה מורכבת יותר:
- וקטורי תמיכה (Support Vectors): הנקודות הקרובות ביותר לקו ההפרדה מכל צד נקראות "וקטורי תמיכה". הן למעשה הנתונים שמכתיבים את מיקום קו ההפרדה.
- מרווח (Margin): המרווח הוא האזור בין שני הקווים שמקבילים לקו ההפרדה ועוברים דרך וקטורי התמיכה. האלגוריתם מחפש להגדיל את המרווח הזה כמה שיותר.
- קו גבול (Hyperplane): הקו עצמו הוא "מישור" בעולם הנתונים. אם יש לנו שני משתנים, הוא קו דו-ממדי. אם יש שלושה משתנים, מדובר במשטח תלת-ממדי. ככל שיש יותר ממדים, הוא הופך ל"היפר-מישור" – גרסה כללית של מישור במרחבים מרובי-ממדים.
SVM יכול להתמודד עם מקרים שבהם אי אפשר להפריד את הנתונים בקו ישר (למשל אם הם מעורבבים). האלגוריתם משתמש בטריק מתמטי שנקרא טרנספורמציית גרעין (Kernel Trick) כדי "להקפיץ" את הנתונים למרחב גבוה יותר, שבו ההפרדה הופכת לקלה יותר. לדוגמה, במקום לחפש קו דו-ממדי, SVM "מעלה" את הנתונים לממד שלישי, שבו אפשר למצוא משטח שמפריד ביניהם.
נניח שאתה רוצה לסווג אנשים לקטגוריות "חרדה" או "דיכאון" על סמך מאפיינים כמו שעות שינה, רמת אנרגיה, שכיחות מחשבות שליליות ורמת פעילות חברתית. האלגוריתם SVM יקבל את הנתונים הללו וינסה למצוא קו או משטח שמפריד בין הקבוצות כך שאנשים עם מאפיינים המזוהים יותר עם חרדה יהיו בצד אחד, ואלו שמאפיינים אותם יותר עם דיכאון יהיו בצד השני.
המטרה היא שהקו הזה יהיה במרחק המרבי מהנקודות הקרובות ביותר מכל צד – כלומר, מאלה שהמאפיינים שלהם נמצאים באזור האפור ויכולים להתאים לשתי הקבוצות. כך האלגוריתם מקטין את הסיכון לטעויות, למשל זיהוי אדם הסובל מדיכאון בטעות כבעל חרדה, ומאפשר לספק אבחנה מבוססת ומדויקת יותר על סמך הנתונים, גם במקרים שבהם הדפוסים חופפים בחלקם.

למידה לא מבוקרת
Clustering (אשכולות)
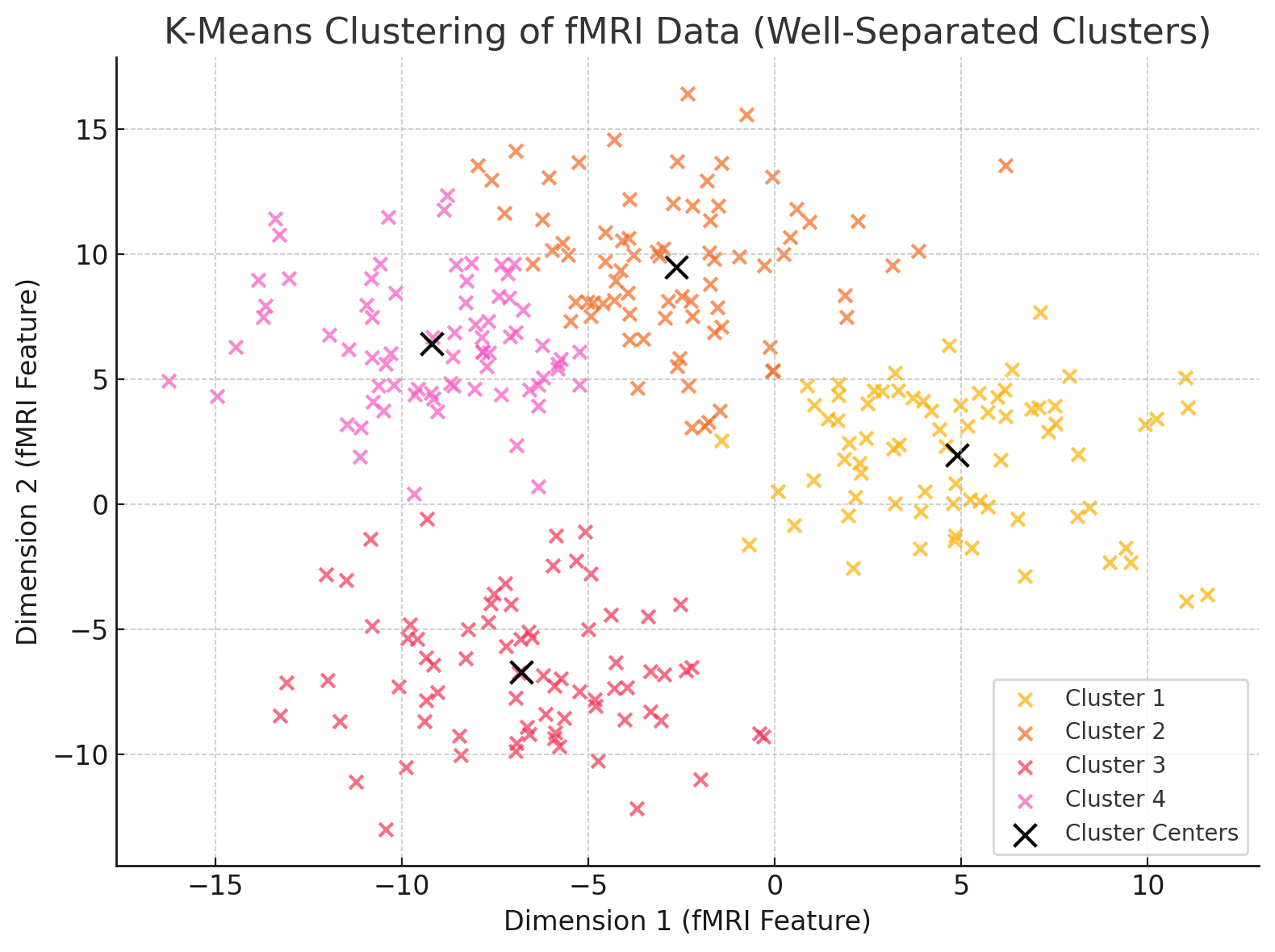
Clustering הוא תהליך שבו אנו מחלקים נתונים לקבוצות (או אשכולות) על סמך מאפיינים משותפים, מבלי להגדיר מראש מהן הקבוצות או כמה יש מהן. אחת השיטות הנפוצות לכך היא K-Means, שבה האלגוריתם מחלק את הנתונים ל-K אשכולות על ידי זיהוי "מרכזים" שמייצגים כל אשכול בצורה הטובה ביותר.
התהליך פועל כך:
- אתחול: האלגוריתם בוחר באופן אקראי K נקודות כמרכזים ראשוניים.
- שייכות: כל נקודת נתונים משויכת לאשכול שהמרכז שלו הכי קרוב אליה מבחינת מרחק (לרוב משתמשים במרחק יוקלידי).
- עדכון: המרכז של כל אשכול מחושב מחדש לפי הממוצע של כל הנקודות שמשויכות אליו.
- חזרה: התהליך חוזר על עצמו עד שהמרכזים מתייצבים ולא משתנים יותר, או עד שמתקיים תנאי עצירה אחר.
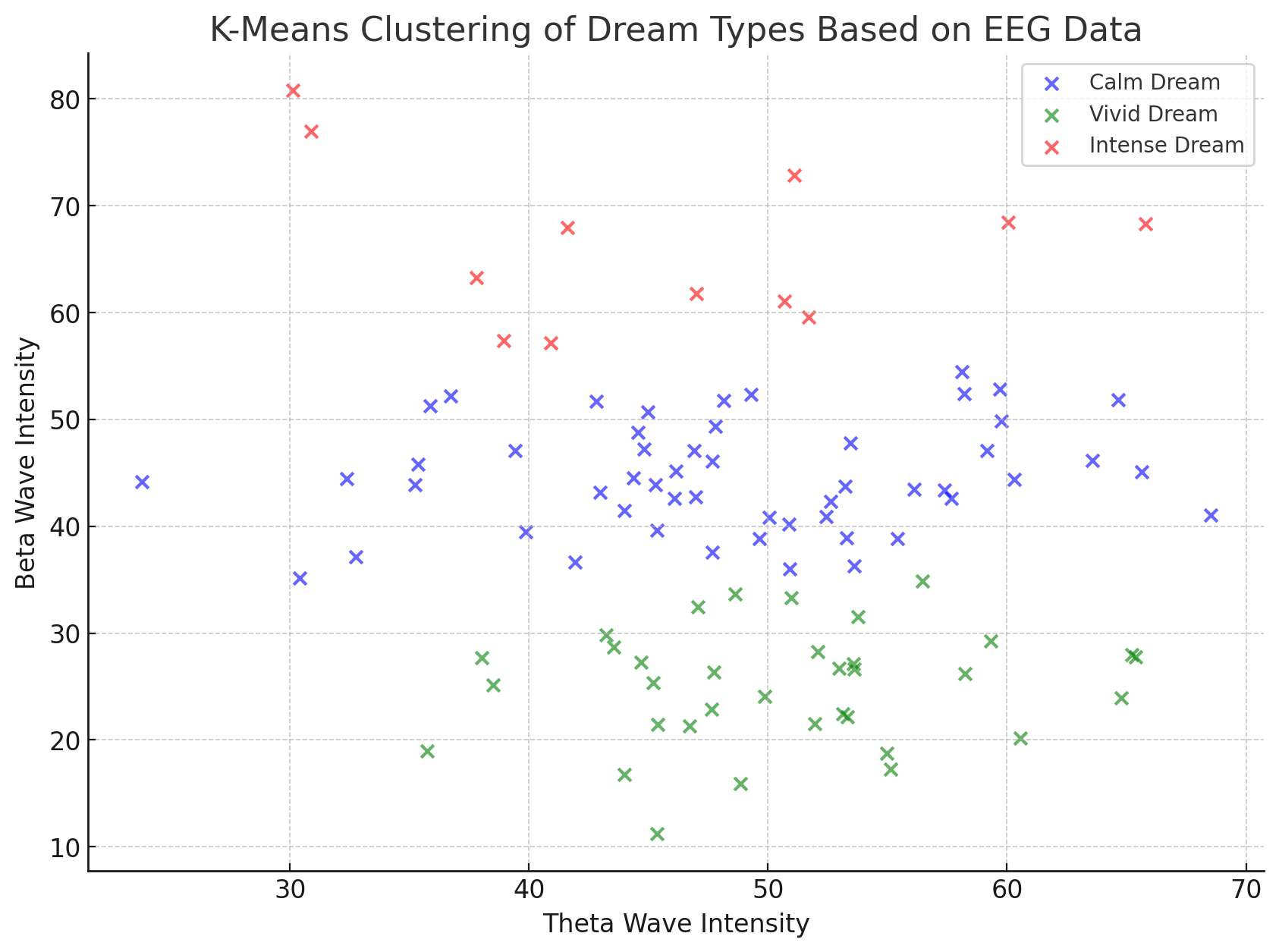
בגרף למטה, כל נקודה מייצגת דגימת נתונים (למשל, תכונות הקשורות לפעילות מוחית בנתוני fMRI), והאלגוריתם חילק את הנתונים לארבעה אשכולות שונים, כאשר כל אשכול מסומן בצבע אחר.
ה-X השחור בכל קבוצה מייצג את מרכז האשכול – הנקודה שמייצגת את הממוצע של כל הדגימות באשכול. תהליך החלוקה יצר אשכולות ברורים ונפרדים, מה שמרמז על כך שהנתונים באמת ניתנים לחלוקה משמעותית על פי המאפיינים שלהם. במקרה זה, ניתן לדמיין שהאשכולות מייצגים קבוצות שונות של פעילות מוחית, כמו תגובות לאזורים ספציפיים במוח תחת משימות שונות.
כך, הגרף מדגים באופן חזותי כיצד K-Means מצליח לחלק את הנתונים לקבוצות בעלות דפוסי דמיון פנימיים, ולמצוא סדר בתוך "רעש" של נתונים מורכבים.
PCA (Principal Component Analysis)
PCA הוא אלגוריתם להפחתת מימדים (Dimensionality Reduction). כלומר, הוא מפשט מערכי נתונים מורכבים ורב-ממדיים על ידי זיהוי המאפיינים (משתנים) החשובים ביותר ושמירה על המידע הקריטי בלבד. המטרה היא להקטין את מספר הממדים בנתונים מבלי לאבד מידע משמעותי – כך שקל יותר לנתח, להמחיש ולהבין את הנתונים.
איך זה עובד:
- זיהוי שונות בנתונים: האלגוריתם מחשב את כמות השונות בין הנתונים (Variance) כדי לזהות אילו משתנים מכילים את מירב המידע ומפרידים בצורה הטובה ביותר בין הדגימות.
- צירים חדשים: האלגוריתם יוצר "צירים חדשים" שנקראים רכיבים עיקריים (Principal Components), שהם שילובים של המשתנים המקוריים. הציר הראשון מייצג את הכיוון שבו יש את מירב השונות בנתונים, הציר השני מכיל את השונות השנייה הכי משמעותית, וכן הלאה.
- הפחתת מימדים: האלגוריתם ממיין את הרכיבים לפי כמות השונות שהם מסבירים ושומר רק על הרכיבים העיקריים ביותר, כך שהמידע שנותר הוא תמצית של הנתונים המקוריים אך בצורה פשוטה יותר.
כאשר יש הרבה מאפיינים (Features) בנתונים, לעיתים יש כפילויות או מאפיינים שמוסיפים "רעש" ולא באמת תורמים להבנה. PCA עוזר להסיר מאפיינים פחות חשובים ולרכז את הנתונים כך שנוכל לבצע ניתוח אפקטיבי עם פחות משתנים.
בגרף המצורף, הנתונים מייצגים אשכולות של סוגי חלומות (חלום רגוע, חלום חי, חלום אינטנסיבי) בהתבסס על נתוני EEG. כל נקודה מייצגת מדידת גלי מוח עם שני משתנים עיקריים: עוצמת גלי תטא (Theta Wave Intensity) ו-עוצמת גלי בטא (Beta Wave Intensity).
במקום לעבוד עם עשרות משתנים ממדידות EEG מורכבות, PCA צמצם את הנתונים לשני משתנים בלבד שמשקפים את המידע העיקרי על אופי החלום. לאחר הפחתת המימדים, האלגוריתם K-Means יצר אשכולות על סמך שני המשתנים הללו וחילק את החלומות לשלוש קבוצות לפי סוגי החלום.
האשכולות בצבעים שונים מראים שהתהליך הצליח לשמור על מבנה ברור למרות הפחתת המימדים – כלומר, החלוקה לסוגי חלומות התבצעה בהצלחה על בסיס המידע הקריטי שנשמר מהנתונים המקוריים.
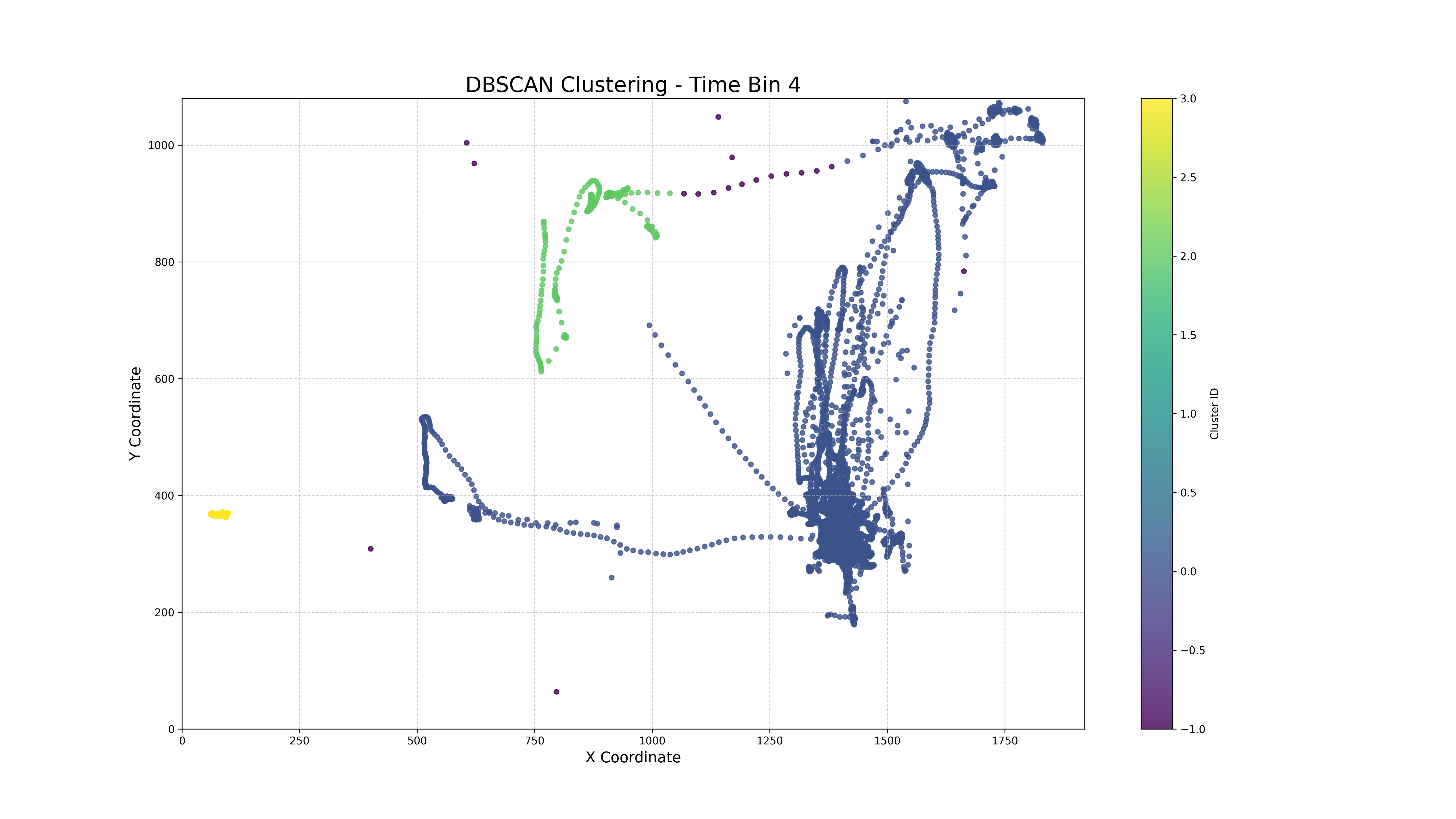
DBSCAN
(Density-Based Spatial Clustering of Applications with Noise) DBSCAN הוא אלגוריתם אשכולות שמתבסס על צפיפות הנתונים כדי לזהות אשכולות בצורה גמישה ומדויקת יותר בהשוואה לאלגוריתמים כמו K-Means. במקום להגדיר מראש מספר אשכולות, DBSCAN מזהה אזורים שבהם הנקודות "צפופות" יחסית ומגדיר אותן כאשכולות, בעוד אזורים דלילים נחשבים ל"רעש" – נקודות שאינן משתייכות לאף אשכול.
איך זה עובד:
- צפיפות מקומית: האלגוריתם מתחיל מנקודת נתונים ובודק כמה נקודות אחרות נמצאות ברדיוס מסוים ממנה (שנקרא ε – אפסילון).
- הגדרת האשכול: אם כמות הנקודות ברדיוס מספיקה (כלומר, היא מעל למספר סף מסוים – MinPts), הנקודה מוגדרת כחלק מ"גרעין" האשכול.
- התרחבות: האלגוריתם ממשיך להרחיב את האשכול סביב הנקודה על ידי חיבור כל הנקודות הצפופות מספיק לאותו האזור, עד שהאשכול ממצה את עצמו.
- נקודות רעש: נקודות שאין סביבן צפיפות מספקת נשארות מבודדות ומסומנות כ"רעש" (Outliers).
DBSCAN יעיל במיוחד כאשר הנתונים מורכבים ואינם נפרדים בקווים ישרים או מוגדרים היטב. למשל, הוא מתאים למקרים שבהם יש אשכולות בצורות לא קונבנציונליות (כמו "עננים" מפותלים) וגם מאפשר לסנן החוצה נקודות חריגות שאינן חלק מתבנית ברורה.
הגרף מציג נתוני מעקב עיניים (Eye Tracking) המחולקים על ידי האלגוריתם DBSCAN. הצירים X ו-Y מייצגים את הקואורדינטות של תנועת העיניים, והצבעים השונים מסמנים אשכולות שונים שהתגלו על ידי האלגוריתם. ניתן לראות אזורים צפופים של נקודות בצבעים שונים (כמו הכחול, הירוק והצהוב) – אלו האשכולות שהתגלו. בנוסף, הנקודות הסגולות הפזורות מסביב הן "רעש", כלומר נקודות שאינן חלק מתבנית ברורה של תנועת עיניים ועשויות לייצג תנועות מקריות או מדידות לא עקביות.היתרון של DBSCAN כאן הוא שהאלגוריתם מצליח לזהות אשכולות מורכבים – גם אם הם אינם עגולים או סימטריים – ולסנן תנועות מבודדות שלא שייכות לדפוסי ההתבוננות העיקריים. כך, ניתן לגלות מסלולי תנועה מרכזיים לעומת נקודות מבט חריגות או זניחות.
למידת חיזוק (Reinfocement Learning)
Q-Learning
Q-Learning הוא אלגוריתם מבוסס חיזוק (Reinforcement Learning) שבו סוכן לומד כיצד לקבל החלטות אופטימליות כדי למקסם תגמול מצטבר לאורך זמן. בניגוד לשיטות שבהן הסוכן מקבל מראש מידע על העולם, ב-Q-Learning הסוכן "לומד תוך כדי" על ידי אינטראקציה עם הסביבה ובחינת ההשלכות של הפעולות שלו.
איך זה עובד:
- פונקציית Q:האלגוריתם משתמש בפונקציה שנקראת Q(s,a), שבה:
- s הוא מצב (State).
- a היא פעולה (Action).
- הפונקציה מחזירה ערך שמייצג את התגמול הצפוי מהבחירה בפעולה a כאשר הסוכן נמצא במצב s.
- למידה מתוך ניסוי וטעייה: הסוכן מבצע פעולה ובודק מה התגמול שהוא מקבל. אם הפעולה הובילה לתגמול גבוה מהמצופה, הערך של הפונקציה Q(s,a) מתעדכן כך שהסוכן ילמד שזו פעולה משתלמת.
- עדכון הערך:לאחר כל פעולה, הערך מחושב כך:
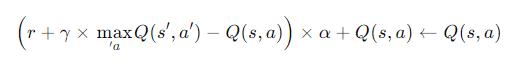
- r – התגמול שהתקבל.
- α – קצב הלמידה (עד כמה הערכים הקודמים משתנים).
- γ – מקדם היוון (משקל שנותנים לתגמולים עתידיים).
- איזון בין חקירה לניצול (Exploration vs Exploitation): האלגוריתם צריך לאזן בין בחירה בפעולות שהוא כבר מכיר כמועילות (ניצול) לבין התנסות באפשרויות חדשות כדי לגלות דרכים טובות יותר לקבל תגמול (חקירה).
מקדם היוון (γ - Gamma) ב-Q-Learning מייצג את החשיבות של תגמולים עתידיים לעומת תגמולים מיידיים. זהו ערך בין 0 ל-1 שקובע עד כמה האלגוריתם "סבלני" כשהוא שוקל את העתיד:
- כאשר γ קרוב ל-0: הסוכן מתמקד בעיקר בתגמולים המיידיים ומתעלם כמעט לחלוטין מתגמולים עתידיים. המשמעות היא שהסוכן יעדיף פעולה שמביאה רווח מהיר, גם אם בטווח הארוך היא פחות משתלמת.
- כאשר γ קרוב ל-1: הסוכן לוקח בחשבון תגמולים עתידיים לאורך זמן ארוך יותר. במקרה כזה, הסוכן מוכן לבצע פעולות שיכולות להוביל להפסד זמני אם הן משרתות מטרה עם רווח גבוה יותר בעתיד.
בחירה בערך גבוה של γ מתאימה למצבים שבהם הסבלנות משתלמת – למשל, בניית אסטרטגיה ארוכת טווח כמו חיסכון כלכלי או תכנון לטיפול בבעיה רפואית לאורך זמן. לעומת זאת, ערך נמוך מתאים למצבים שבהם יש חשיבות לפעולה מיידית, כמו התחמקות ממכשול פתאומי בזמן משחק מחשב.
באלגוריתם Q-Learning, מקדם היוון מאפשר לאזן בין תגמולים שמגיעים כאן ועכשיו לבין תגמולים שמגיעים בטווח הארוך, ובכך לשקול את האסטרטגיה המתאימה ביותר לכל סיטואציה.
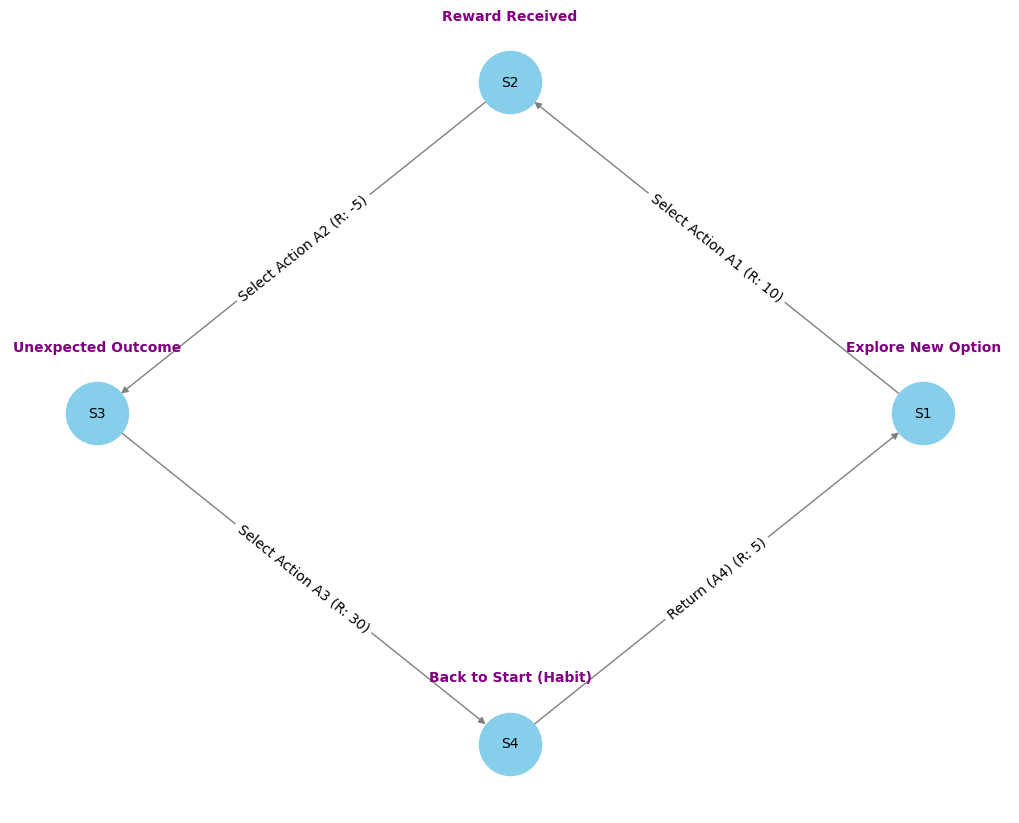
בגרף שמוצג, יש ארבעה מצבים (S1 עד S4), וכל אחד מהם מחובר לפעולות שונות עם ערכי תגמול. לדוגמה:
- ממצב S1 הסוכן יכול לבחור "לחקור אפשרות חדשה" ולהתקדם ל-S2, שם יש תגמול גבוה יותר (10 נקודות).
- לעומת זאת, חזרה למצב ההתחלתי S4 עשויה להיות פעולה הרגלית שמחזירה אותו עם תגמול נמוך יותר.
המעברים והתגמולים מאפשרים לסוכן ללמוד אילו פעולות מובילות לתגמול מקסימלי לאורך זמן, וכך הוא לומד להימנע מ"מעגלי הרגל" ולעדיף פעולות שמובילות ל"פרסים" גבוהים.
בסופו של דבר, האלגוריתם מבנה את הידע שלו כך שבכל מצב הוא יודע לבחור את הפעולה שמובילה לתוצאה הטובה ביותר, גם אם נדרשת חקירה ראשונית כדי ללמוד זאת.
Deep Q-Networks (DQN)
DQN הוא שדרוג של אלגוריתם Q-Learning שמשתמש ברשתות נוירונים עמוקות (DNN) כדי להתמודד עם בעיות מורכבות שבהן יש מספר עצום של מצבים ופעולות אפשריות. כאשר Q-Learning קלאסי שומר טבלה של כל המצבים והפעולות, ב-DQN הרשת הנוירונית משמשת בתור "מפת תחזיות" – היא מקבלת את המצב הנוכחי ומחזירה ערכים שמייצגים את התגמול הצפוי עבור כל פעולה אפשרית.
לדוגמה, בדומה ל-DQN שמתמודד עם נהיגה אוטונומית באמצעות ניתוח מצב הדרך (מהירות, מכשולים ומיקום), מנוע שחמט כמו AlphaZero מתמודד עם מצב הלוח (מיקום הכלים, סכנות אפשריות, ואפשרויות התקפה) ומחשב את הערך של כל מהלך אפשרי.
בעוד שב-DQN הרשת הנוירונית מחזירה את הערכים הצפויים של פעולות כמו האצה או בלימה, מנוע השחמט מעריך מהלכים כמו "הזזת הצריח" או "הקרבת פרש" כדי למצוא את המהלך שיוביל לתוצאה הטובה ביותר.
ההבדל המרכזי הוא שבשחמט, המנוע מחשב רצפים ארוכים של מהלכים ותוצאותיהם העתידיות, בעוד ב-DQN הדגש הוא על קבלת החלטה מיידית תוך כדי חקירה ולמידה מתמשכת של המצבים בשטח.
איך זה עובד?
- קלט (Input): הסוכן מקבל ייצוג של המצב הנוכחי בסביבה, הכולל מאפיינים כמו מהירות, מיקום, או מידע על מכשולים.
- עיבוד במודל נוירוני: רשת הנוירונים מעבדת את הנתונים דרך שכבות חישוביות שמייצרות תחזיות לערכי Q עבור כל פעולה.
- בחירת פעולה: האלגוריתם בוחר פעולה לפי ערכי Q – לרוב בוחרים את הפעולה עם הערך הגבוה ביותר ("ניצול"), אך לעיתים גם מנסים פעולות חדשות כדי להרחיב את הלמידה ("חקירה").
- עדכון למידה: לאחר ביצוע הפעולה, הסוכן מקבל תגמול מהסביבה ומעדכן את הרשת הנוירונית בהתאם לתוצאה, תוך שימוש במשוואת Q-Learning עם רשת הלמידה.
DQN מתאים לסביבות מורכבות שבהן כמות המצבים כה גדולה עד שלא ניתן לשמור טבלה מפורטת של כל האפשרויות. לדוגמה, במשחקים כמו "דמקה" או "נחש", הסוכן לומד אסטרטגיה מיטבית באמצעות ניסוי וטעייה תוך הסתמכות על רשת נוירונים שיודעת להעריך את המהלכים הטובים ביותר.
הגרף מתאר מערכת קבלת החלטות לרכב אוטונומי המשתמש ב-DQN.
- בקלט, הרכב מקבל נתונים מחיישנים כמו מהירות נוכחית, קרבה למכשולים, ומיקום בתוך הנתיב.
- הנתונים עוברים דרך "צמתים" המייצגים שכבות החלטה בתוך רשת הנוירונים.
- הפלט כולל פעולות אפשריות כמו האצה, בלימה או פנייה (הפלטים Q1 עד Q4 בגרף).
הרשת מחליטה איזו פעולה לבצע בהתאם לתנאי הדרך ולמידע מהחיישנים. למשל, אם הרכב מזהה מכשול קרוב, הוא עשוי לבחור לפנות ימינה או להאט כדי למנוע תאונה.
DQN עוזר לרכב ללמוד מהמצבים שהוא חווה כדי להימנע ממצבים בעייתיים ולשפר את ביצועיו לאורך זמן, בדומה לאופן שבו נהג לומד לשפר את הנהיגה שלו בהתאם להתנסות.

רשתות נוירונים בעיבוד תמונה וקול: היישומים המתקדמים
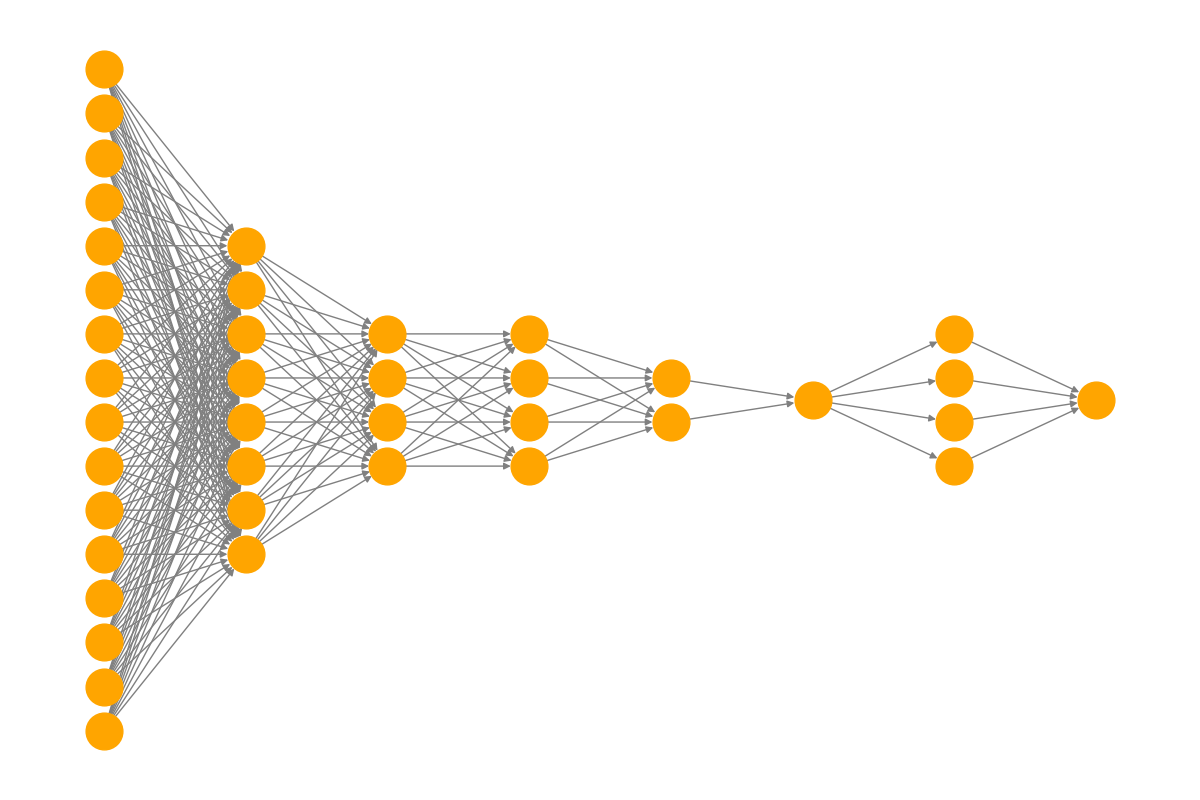
רשתות נוירונים מלאכותיות (ANN)
רשתות נוירונים מלאכותיות (ANN) הן מודלים חישוביים שמדמים את פעולת המוח האנושי באמצעות שכבות של "נוירונים" מלאכותיים. המטרה של רשת נוירונים היא ללמוד כיצד למפות בין קלט (Input) לפלט (Output) במשימות כמו סיווג תמונות, זיהוי קול, ניתוח טקסטים ועוד.
מבנה רשת נוירונים:
- שכבת הקלט (Input Layer): בשכבה זו נמסרים הנתונים הראשוניים לרשת – לדוגמה, בתמונת זיהוי פנים, כל פיקסל מהתמונה הוא ערך בקלט. בגרף ניתן לראות מספר רב של ערכי קלט (מסומנים כ-Input).
- שכבות נסתרות (Hidden Layers): השכבות שבין הקלט לפלט מעבדות את המידע ומבצעות חישובים מורכבים. כל נוירון בשכבה מחובר לנוירונים מהשכבה הקודמת ושולח מידע לשכבה הבאה. התהליך הזה נקרא העברת אותות ומבוסס על פונקציות מתמטיות. ניתן לראות בגרף כמה שכבות נסתרות עם מספר רב של קשרים.
- שכבת הפלט (Output Layer): בשכבה זו הרשת מחזירה את התוצאה הסופית – לדוגמה, סיווג התמונה כ"חתול" או "כלב", או קביעה אם טקסט שייך לקטגוריה מסוימת.
כל נוירון מקבל את המידע מהנוירונים שמחוברים אליו, מבצע עליו חישוב (לרוב מדובר בשקלול של הנתונים והעברת התוצאה דרך פונקציה מתמטית), ושולח את התוצאה לנוירון הבא. במהלך האימון, הרשת לומדת על ידי התאמת המשקלים שמחברים בין הנוירונים, כך שהפלט של הרשת יתקרב ככל האפשר לערך האמיתי הרצוי.
בגרף ניתן לראות מבנה של רשת נוירונים עמוקה (Deep Neural Network), שבה יש שכבת קלט בצד שמאל, שכבות נסתרות רבות עם מספר גבוה של קשרים פנימיים, ושכבת פלט בודדת בצד ימין שמחזירה את התוצאה.
רשת כזו מתאימה למשימות מורכבות כמו עיבוד תמונה או ניתוח קול, שבהן נדרשת יכולת למידה עמוקה כדי להבין דפוסים מורכבים בנתונים. ככל שיש יותר שכבות נסתרות, הרשת יכולה ללמוד דפוסים מורכבים יותר – אך גם דורשת זמן חישוב רב יותר ואימון ממושך.
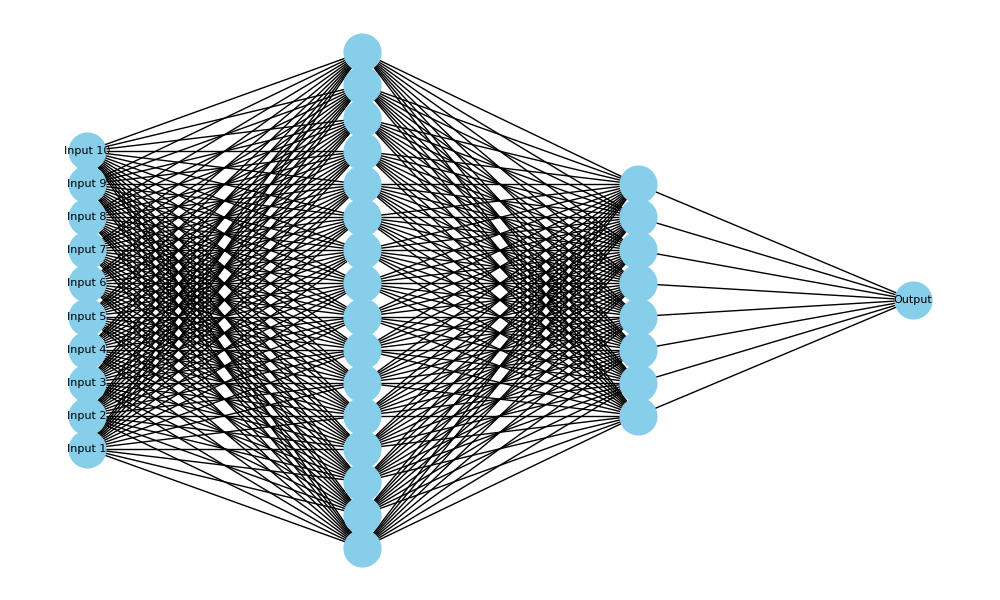
CNN (Convolutional Neural Networks)
רשתות נוירונים קונבולוציוניות (CNN) הן סוג מיוחד של רשתות נוירונים מלאכותיות, שתוכננו במיוחד למשימות עיבוד תמונה. בניגוד לרשתות רגילות (Fully Connected), CNN משתמשות בשכבות ייחודיות בשם "שכבות קונבולוציה" שמסוגלות לזהות מאפיינים מקומיים בתוך התמונה, כמו קצוות, פינות, צורות וגופים מורכבים.
איך זה עובד:
- שכבת קונבולוציה: בשלב הראשון, הרשת מקבלת תמונה בתור קלט ומפעילה פילטרים (קונבולוציות) שסורקים את התמונה במקטעים קטנים. כל פילטר מזהה דפוסים מסוימים – לדוגמה, פילטר אחד עשוי לזהות קווי מתאר אופקיים, בעוד שפילטר אחר יזהה עיגולים או קווים אלכסוניים.
- שכבת Pooling (מיצוי): לאחר מכן, שכבת ה-Pooling מפחיתה את ממדי המידע כדי להקטין את כמות החישובים ולהתמקד באזורים החשובים בתמונה. לרוב משתמשים ב-Max Pooling – שמירת הערך המקסימלי במקטע קטן של התמונה.
- שכבות Fully Connected: החלק הסופי ברשת CNN הוא שכבות מחוברות מלאות (כמו ברשת רגילה), שבהן המידע המעובד הופך לסדרה של נוירונים שמייצגים קטגוריות שונות (למשל, "חתול" או "כלב" במקרה של סיווג תמונות).
בגרף ניתן לראות מבנה המזכיר מבנה של רשת CNN.
- בצד שמאל מופיעה שכבת הקלט, שמייצגת נתוני פיקסלים בתמונה.
- בהמשך מופיעות שכבות שמייצגות את שלבי הקונבולוציה והמיצוי (הפחתה של ממדים), כאשר כל שכבה קטנה יותר מהשכבה הקודמת – עד שמתקבלת שכבה קטנה מאוד שמכילה מידע מרוכז וקריטי על מאפייני התמונה.
- לאחר מכן, יש שכבות fully connected שמייצרות את ההחלטה הסופית – כלומר, סיווג התמונה לקטגוריה מסוימת.
מבנה כזה מתאים למשימות כמו זיהוי אובייקטים או סיווג פנים, כי הרשת יודעת "לפרק" את התמונה לחלקים קטנים ולזהות תבניות שנמצאות באזורים שונים בתמונה, ובכך לשמור על דיוק גבוה בעיבוד נתונים חזותיים מורכבים.
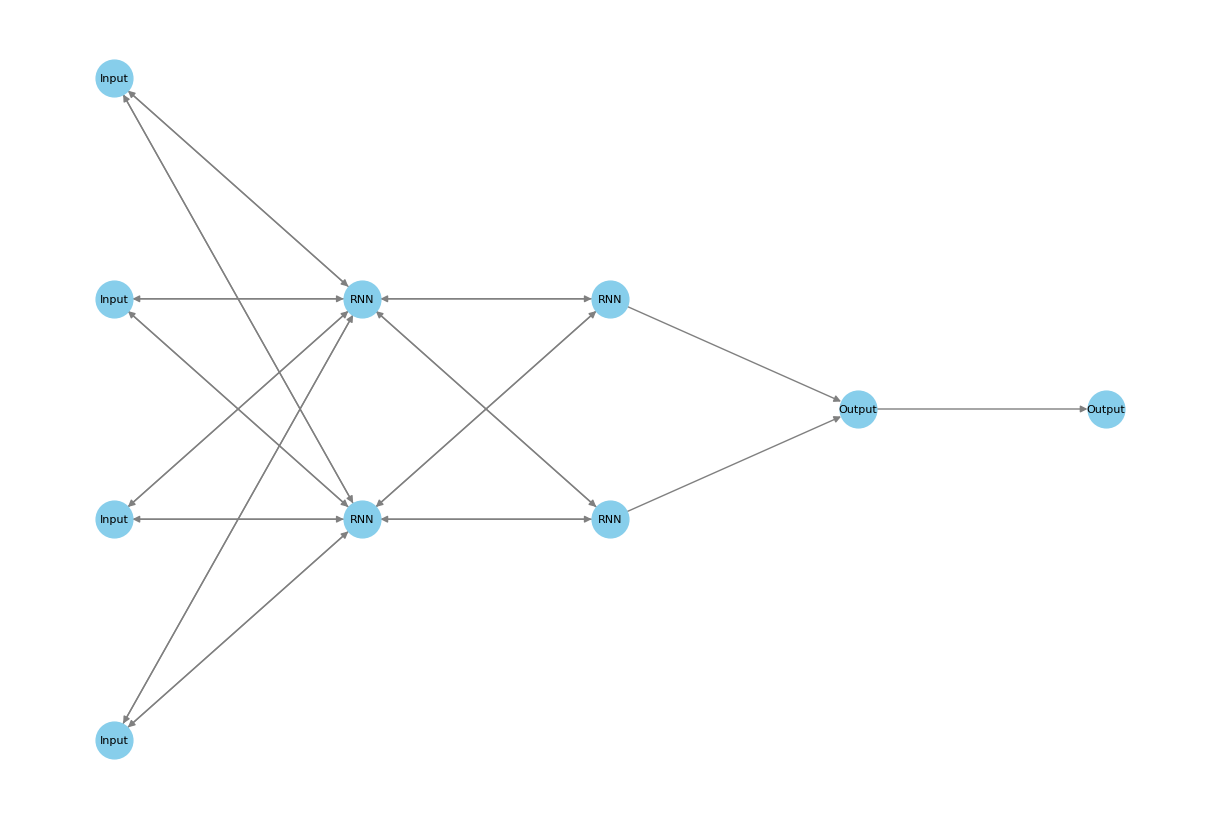
RNN (Recurrent Neural Networks)
RNN (רשתות נוירונים חוזרות) הן סוג של רשתות נוירונים שמתאימות במיוחד למשימות שבהן יש חשיבות לסדר המידע ולהקשר של הנתונים לאורך זמן. בניגוד לרשתות רגילות שבהן הנתונים זורמים בכיוון אחד משכבת הקלט לשכבת הפלט, ב-RNN המידע זורם גם אחורה, כלומר, הרשת שומרת "זיכרון" מהחישובים הקודמים כדי להשפיע על החישובים העתידיים.
איך זה עובד:
- קשרים חוזרים: כל נוירון בשכבה החוזרת (Recurrent Layer) מקבל לא רק את הקלט מהשכבה הקודמת אלא גם את הפלט של עצמו מהשלב הקודם. זה מאפשר לרשת לזכור את המידע הקודם ולשלב אותו עם המידע החדש.
- עיבוד סדרתי: ברשתות RNN, הנתונים מוזרמים בצורה סדרתית – צעד אחרי צעד. לדוגמה, בעיבוד טקסט, כל מילה מוזנת בתור קלט לפי הסדר, והרשת מעדכנת את "הזיכרון" שלה בהתאם למילה הקודמת.
- שמירה על הקשר: מבנה זה מתאים במיוחד למשימות שבהן יש תלות בסדר של הנתונים, כמו תרגום שפה (שבו המשמעות משתנה בהתאם לסדר המילים), חיזוי סדרות זמן (כמו תחזיות מניות), או זיהוי דיבור.
בגרף ניתן לראות רשת RNN שבה יש שכבת קלט (Input), שכבות חוזרות (RNN) שמחוברות גם לעצמן וגם קדימה, ושכבת פלט (Output).
- שכבת ה-RNN מקבלת את הקלט ומחזירה מידע שמבוסס גם על המידע הנוכחי וגם על ה"זיכרון" שלה מהשלבים הקודמים.
- הקשרים החוזרים (הלולאות) מייצגים את תהליך השמירה על הקשר למידע הקודם.
רשת כזו מתאימה לעיבוד נתונים רציפים שבהם יש תלות בין השלבים, כמו קריאת משפט שבו יש משמעות להקשר של המילים הקודמות. לדוגמה, בעיבוד טקסט, המילה "חתול" עשויה לשנות את המשמעות של המילה "רץ" במשפט בהתאם להקשר המילים שבאו לפני.
אלגוריתמים היברידיים ושיטות מתקדמות
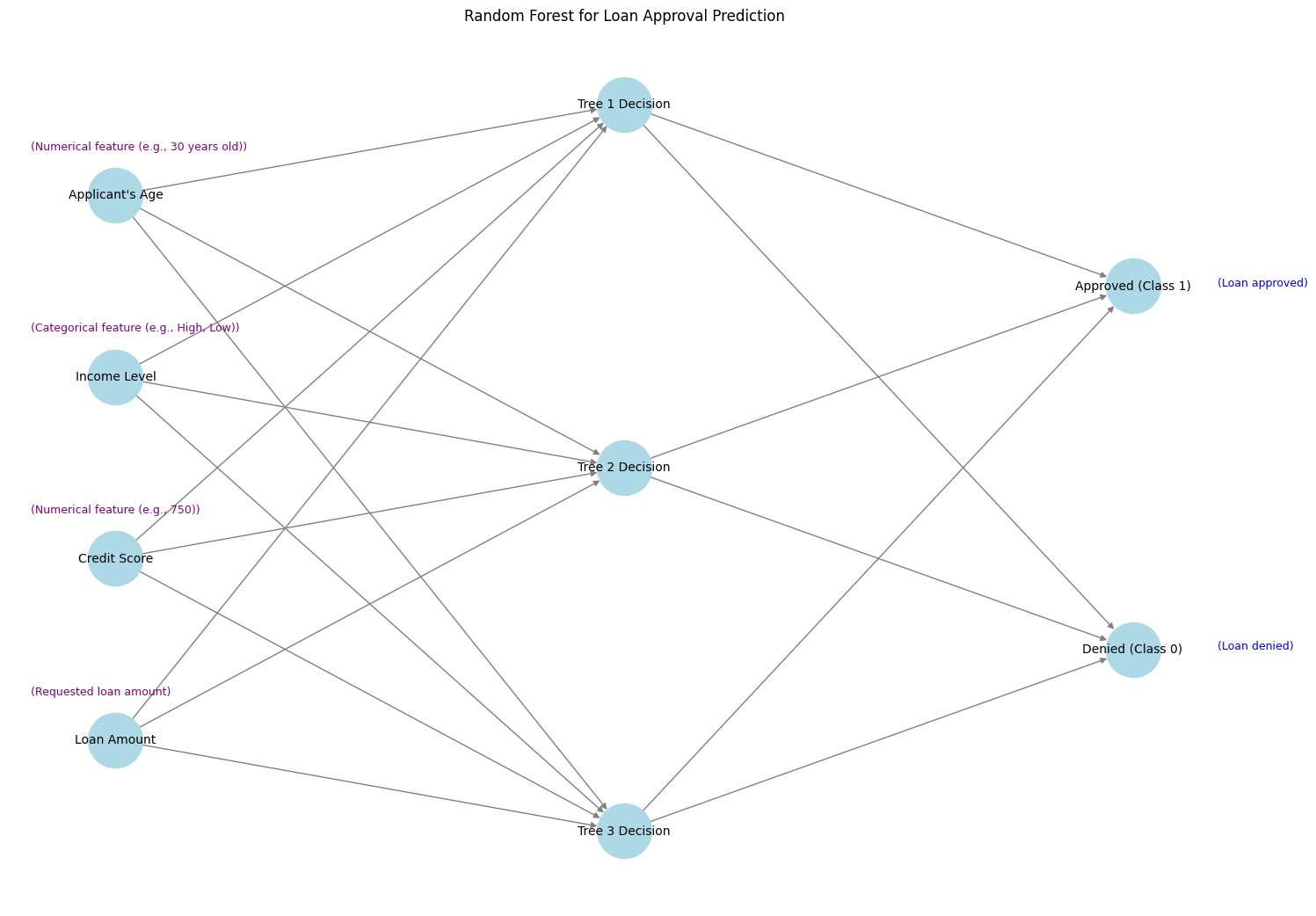
Random Forest
Random Forest הוא אלגוריתם שמבוסס על שילוב של מספר עצי החלטה כדי לשפר את הדיוק של התחזיות ולהפחית הטיות. במקום להסתמך על עץ החלטה יחיד, האלגוריתם יוצר "יער" של עצים, וכל עץ מקבל חלק שונה מהנתונים ומתבקש לתת תחזית. התחזית הסופית מתקבלת לפי רוב ההצבעות של כל העצים (ברגרסיה הממוצע של התחזיות).
איך זה עובד?
- יצירת תת-מדגמים: האלגוריתם בונה מספר עצי החלטה שונים כאשר כל עץ מאומן על מדגם אקראי (Bootstrapping) של הנתונים.
- פיצול אקראי: בכל צומת בעץ, האלגוריתם בוחר באופן אקראי תכונה אחת מתוך קבוצה קטנה של תכונות, כדי ליצור גיוון בין העצים.
- שילוב התוצאות: בתחזית סופית, האלגוריתם "שואל" את כל העצים ביער ומקבל החלטה סופית לפי הצבעת הרוב (לסיווג) או ממוצע (לרגרסיה).
עץ החלטה יחיד עלול להיות רגיש מאוד לשינויים בנתונים ולהטות את התחזיות בהתאם לאותם נתונים ספציפיים. על ידי יצירת אוסף של עצים עצמאיים וקבלת תחזית סופית המבוססת על כולם, Random Forest מונע הטיות ומקטין את הסיכוי להחלטות שגויות.
בגרף המוצג, ניתן לראות כיצד האלגוריתם מחליט אם לאשר או לדחות בקשת הלוואה על בסיס מספר פרמטרים:
- שכבת הקלט: הנתונים כוללים מאפיינים כמו גיל, דירוג אשראי, רמת הכנסה, סכום מבוקש ועוד.
- עצים (Tree Decision Nodes): ישנם מספר עצי החלטה, וכל עץ מקבל החלטה באופן עצמאי על בסיס המדגם שלו. למשל, אחד העצים מתמקד בפרטים כמו סכום ההלוואה והכנסה, ואחר מסתמך על דירוג האשראי.
- שכבת הפלט: הפלט הסופי משלב את ההחלטות של כל העצים וקובע אם ההלוואה מאושרת (Approved) או נדחית (Denied).
השימוש במספר עצים מאפשר "למזג" את השיקולים ולהגיע לתוצאה אמינה יותר מאשר הסתמכות על עץ בודד, שמושפע יותר משינויים בנתונים.
XGBoost
XGBoost הוא אלגוריתם Boosting מתקדם שנועד לשפר את הדיוק והביצועים של מודלים באמצעות שילוב של עצים רבים, כאשר כל עץ מתקן את הטעויות של העצים הקודמים. בניגוד לשיטות Boosting רגילות, XGBoost יעיל מאוד מבחינת זמן עיבוד ומשתמש בטכניקות אופטימיזציה שמאפשרות לו לפעול מהר יותר ולהתמודד עם כמויות נתונים גדולות מאוד.
איך זה עובד:
- Boosting (חיזוק): האלגוריתם בונה עצי החלטה באופן סדרתי, כאשר כל עץ מנסה לשפר את השגיאה של העצים שקדמו לו.
- עדכון משקלים: בכל שלב, XGBoost נותן משקל גבוה יותר לדוגמאות שבהן התוצאה הייתה שגויה, כך שהעצים הבאים יתמקדו בהן כדי לשפר את הדיוק.
- שימוש באובדן (Loss Function): האלגוריתם מחשב בכל שלב פונקציית אובדן שמייצגת את מידת השגיאה ומבצע אופטימיזציה כדי למזער אותה.
- Tree Pruning: האלגוריתם מבצע גיזום חכם של ענפים מיותרים בעץ כדי להקטין סיכון ל-Overfitting (למידת יתר).
XGBoost ידוע בזכות היכולת שלו להשיג ביצועים גבוהים בזמן קצר ובזכות היכולת להתמודד עם נתונים מורכבים ומספר רב של מאפיינים. זו הסיבה שהאלגוריתם נמצא בשימוש נרחב בתחרויות למידת מכונה, כולל תחרויות של Kaggle.
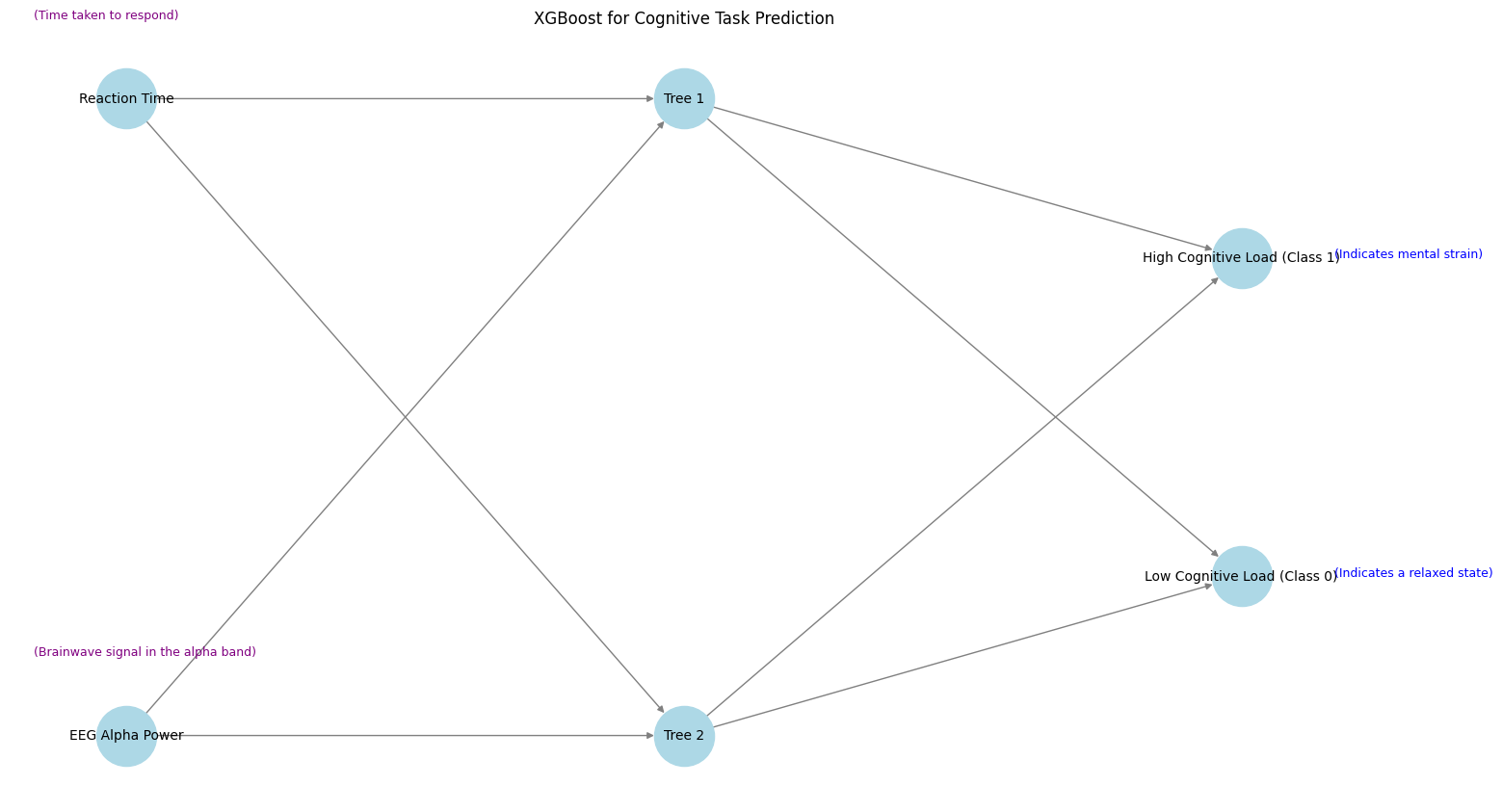
בגרף ניתן לראות יישום של XGBoost במשימה של חיזוי עומס קוגניטיבי (Cognitive Load) בהתבסס על נתוני EEG וזמן תגובה:
- שכבת הקלט: הנתונים כוללים מאפיינים כמו זמן תגובה ועוצמת גלי אלפא (המעידה על מצב רגיעה או ריכוז).
- עצים (Tree 1, Tree 2): כל עץ מנסה לחזות את רמת העומס הקוגניטיבי על בסיס המאפיינים שניתנו לו.
- שכבת הפלט: הפלט של האלגוריתם מסווג לשתי קטגוריות: עומס קוגניטיבי גבוה (Class 1) ועומס קוגניטיבי נמוך (Class 0).
בכל שלב, העצים עובדים יחד כדי להקטין את השגיאה ולבצע תחזית מדויקת ככל האפשר על פי הדפוסים שנמצאים בנתונים. בכך, האלגוריתם משתמש בחיזוקים חוזרים כדי לדייק את הסיווג הסופי, למשל – זיהוי אם נבדק נמצא במצב "עומס מנטלי" או "רגיעה" במהלך משימה קוגניטיבית.
GAN (Generative Adversarial Networks)
GAN הוא מודל למידת מכונה שמורכב משני חלקים עיקריים:
- גנרטור (Generator): אלגוריתם שמטרתו לייצר נתונים חדשים, "מזויפים", שמדמים את הנתונים האמיתיים.
- דיסקרימינטור (Discriminator): אלגוריתם שמטרתו להבחין בין נתונים אמיתיים לנתונים מזויפים שנוצרו על ידי הגנרטור.
שני האלגוריתמים פועלים בתהליך למידה שבו הם מתחרים זה בזה: הגנרטור מנסה "לרמות" את הדיסקרימינטור ולגרום לו להאמין שהנתונים המיוצרים הם אמיתיים, בעוד שהדיסקרימינטור מנסה לשפר את היכולת שלו להבחין בין נתונים אמיתיים למזויפים.
- הגנרטור: מתחיל מוקטור אקראי של "רעש" ומעבד אותו דרך שכבות כדי ליצור נתונים שנראים כמו הנתונים האמיתיים (למשל, אותות גלי מוח מלאכותיים).
- הדיסקרימינטור: מקבל הן את הנתונים המיוצרים והן נתונים אמיתיים ובוחן האם הם נראים אמיתיים או מזויפים.
- אימון משולב: התהליך חוזר על עצמו – הגנרטור לומד לייצר נתונים משופרים, והדיסקרימינטור משתפר בזיהוי נתונים מזויפים – עד שהגנרטור מצליח לייצר נתונים שהדיסקרימינטור מתקשה להבדיל בינם לבין נתונים אמיתיים.
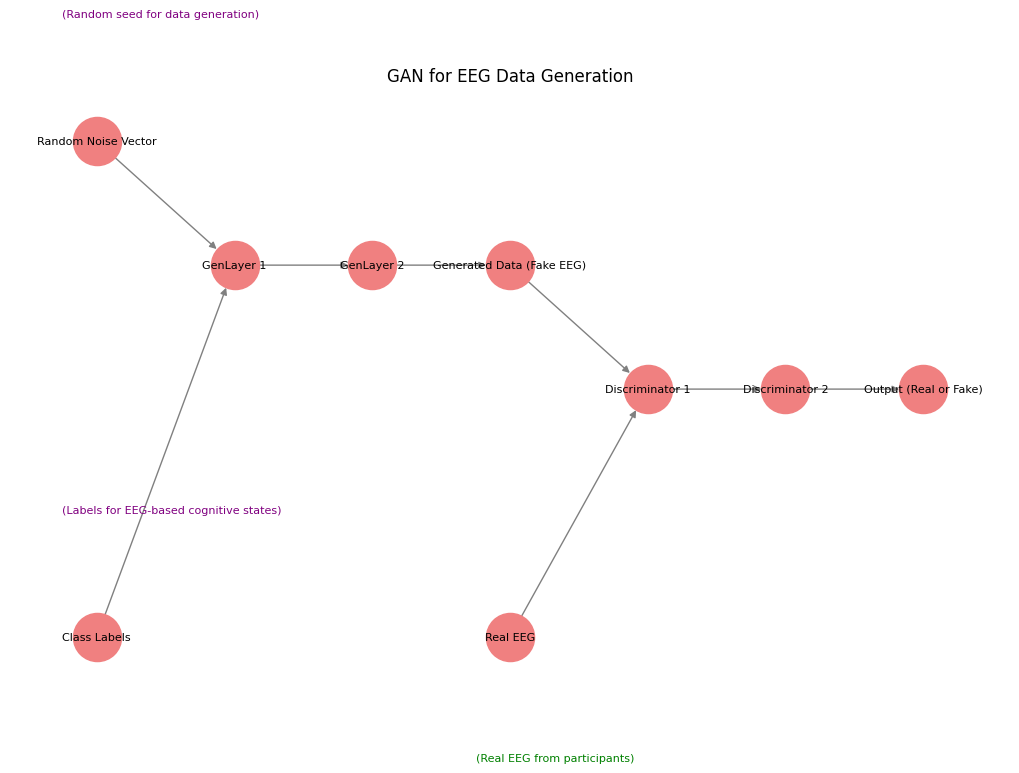
בגרף ניתן לראות מבנה של GAN ליצירת נתוני EEG מלאכותיים:
- וקטור הרעש האקראי (Random Noise Vector): זהו הקלט של הגנרטור – ערכים אקראיים שממנו הגנרטור מתחיל ליצור אותות EEG.
- שכבות הגנרטור (GenLayers): השכבות הללו מעבדות את הרעש ויוצרות נתוני EEG סינתטיים (Generated Data).
- הדיסקרימינטור: מקבל שני סוגי נתונים – נתונים אמיתיים של EEG מהמשתתפים, ונתונים מזויפים שהגנרטור ייצר – ומנסה להחליט אם כל סט נתונים הוא אמיתי או מזויף.
- שכבת הפלט: מחזירה החלטה – האם הנתונים הם אמיתיים או מזויפים.
GAN משמשים ליצירת נתונים מלאכותיים אך מציאותיים למטרות כמו שיפור מערכות זיהוי, יצירת תמונות וידאו מלאכותיות, ואפילו הרחבת מערכי נתונים קטנים – במקרה הזה, ליצירת נתוני EEG נוספים כדי להעשיר ניסויים נוירופיזיולוגיים.
למשל, ניתן להשתמש ב-GAN כדי לדמות מצב של עומס קוגניטיבי גם אם יש רק כמות קטנה של מדידות אמיתיות.
חשיבותה של למידת מכונה בעידן הבינה המלאכותית
בעידן שבו כמות המידע הזמינה גדלה בקצב מסחרר, למידת מכונה מהווה כלי מרכזי שמאפשר להפיק תובנות מנתונים מורכבים ולבצע תחזיות מדויקות. בתחומי מחקר, בריאות הנפש, וטכנולוגיות מתקדמות, למידת מכונה היא כבר לא רק אופציה – היא הכרח. אלגוריתמים כמו Random Forest, DQN, ו-GAN מאפשרים לא רק ניתוח אלא גם יצירת מידע חדש, מה שהופך אותה לייחודית.
חוקרים ואקדמאים יכולים להשתמש בלמידת מכונה כדי לנתח כמויות עצומות של נתונים – דבר שהיה בעבר בלתי אפשרי או גזל משאבים רבים.
במדעי החברה והפסיכולוגיה ניתן לזהות דפוסי התנהגות נסתרים, לשלב מדידות EEG או כלים אובייקטיבים אחרים כדי לנטר רמות עומס קוגניטיבי או רגשי או מחלות, ולבנות מודלים שמנבאים הצלחה בטיפול פסיכולוגי.
בתחומי הנוירופיזיולוגיה אלגוריתמים של למידת מכונה מסוגלים לעבד ולמיין אותות מוחיים כמו EEG ו-fMRI כדי לזהות מצבים נוירולוגיים מורכבים ולהסיק מסקנות מדויקות יותר על תפקודי מוח.
פסיכולוגים ומטפלים יכולים להשתמש במודלים כמו RNN ו-CNN כדי לשפר אבחנות, להבין טוב יותר את השפעת התערבויות טיפוליות ולנטר שינויים במהלך טיפול באופן מבוסס נתונים.
לדוגמה: אלגוריתם XGBoost יכול לחזות עומס קוגניטיבי במהלך משימות טיפוליות ולהתריע על עייפות מנטלית או קשב ירוד. שימוש במודלים של GAN יכול להעשיר מחקרים פסיכולוגיים באמצעות יצירת סימולציות של דפוסי EEG מורכבים – גם כשיש דגימות קטנות של משתתפים.
אנשי דאטה משתמשים בלמידת מכונה כדי לבצע ניתוחים סטטיסטיים, לאמן מודלים חזויים ולהבין אילו משתנים משפיעים על תוצאות עסקיות או מחקריות.
למשל: אלגוריתמים כמו Random Forest עוזרים לסווג נתונים רועשים בצורה אפקטיבית ולמנוע בעיות של Overfitting. כלי Boosting כמו XGBoost מאפשרים להגיע לתחזיות מדויקות ולמזער טעויות בתחומים כמו כלכלה, ניתוח מניות, וזיהוי הונאות.
סיכום
למידת מכונה לא רק מאיצה תהליכי מחקר אלא גם משדרגת אותם, ומאפשרת למידה והפקת תובנות מדאטה שבעבר היה קשה לעיבוד. עבור אנשי טיפול ומחקר, היא פותחת דלתות לניתוח רגשות, התנהגות, וקוגניציה ברזולוציות חדשות. עבור אנשי דאטה, היא כלי חיוני לניהול מידע והפקת תחזיות מדויקות – וכך, הופכת את האינטואיציה האנושית לכלי מבוסס נתונים שמחזק את קבלת ההחלטות בתחומי הבריאות, הפסיכולוגיה, והמחקר האקדמי.